軸屋敬介 | Keisuke Jikuya
Home
Note
Blog
Post
RedCaps: Web-curated image-text data created by the people, for the people
RedCaps: Web-curated image-text data created by the people, for the people
https://redcaps.xyz/
Jul 3, 2023
Dataset, Caption,
NeurIPS (2021)
概要
ビジョンと言語のタスクのための大規模データセットは、検索エンジンをクエリにしたりHTMLのaltテキストを収集することで構築されているが、ウェブデータはノイズが多いため、品質を維持するために複雑なフィルタリングパイプラインが必要
最小限のフィルタリングで高品質なデータを収集するための代替データソースを探索
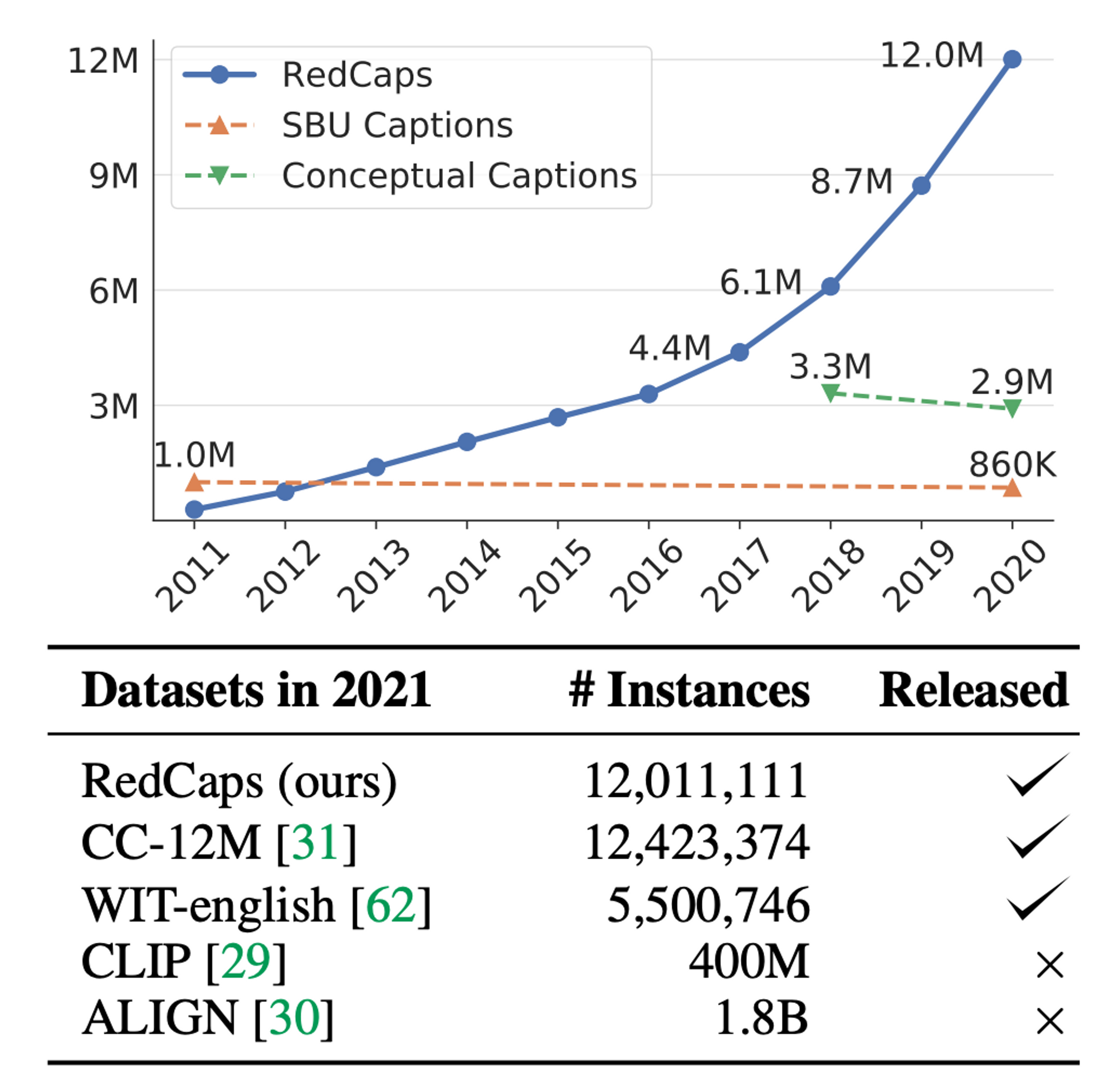
Redditから収集された1200万の画像とキャプションのペアのRedCapsという大規模なデータセットを紹介
新規性・差分
Redditから収集された画像とキャプションのペアで構成
独自のデータ収集パイプラインやフィルタリング手法を使用して高品質なデータを提供
アイデア
パイプライン
ステップ1:Subredditの選択
手動で選ばれた一連のSubredditからデータを収集
Subredditの選択により、個々のインスタンスに注釈を付けることなく、データセットの構成を調整することができる
人々の画像を共有したり、コメントしたりすることを目的とするサブレディットは除外
ステップ2:画像投稿のフィルタリング
PushshiftとRedditのAPIを使用して、選択したSubredditに投稿されたすべての画像投稿をダウンロード
画像はReddit、Imgur、Flickrの3つのドメインにホストされているもののみ収集
人気のないコンテンツや不適切なコンテンツを避けるために、2つ未満の評価やNSFWマークのある投稿は除外
ステップ3:キャプションのクリーニング
Redditの投稿タイトルは他の大規模なソース(例:altテキスト)に比べてノイズが少ないため、テキストのクリーニングは最小限
キャプションを小文字に変換し、文字のアクセント、絵文字、非ラテン文字を削除
括弧で囲まれた部分を簡単なパターンマッチングで削除
ソーシャルメディアのハンドル(’@’で始まる単語)を[USR]トークンに置き換え、ユーザーのプライバシーを保護し重複を減らす
プライバシー保護
RetinaFaceで信頼度0.9以上の顔が検出されたものを削除
NSFW画像
InceptionV3でポルノまたはヘンタイとして検出されたものを削除
Potentially derogatory language
軽蔑的な言葉を含むものを削除
Consent
ユーザーはデータセットになることを同意していないため、Redditの投稿が消えたらデータセットから削除され、削除申請できるフォームも用意
結果
image-textデータセットとの比較
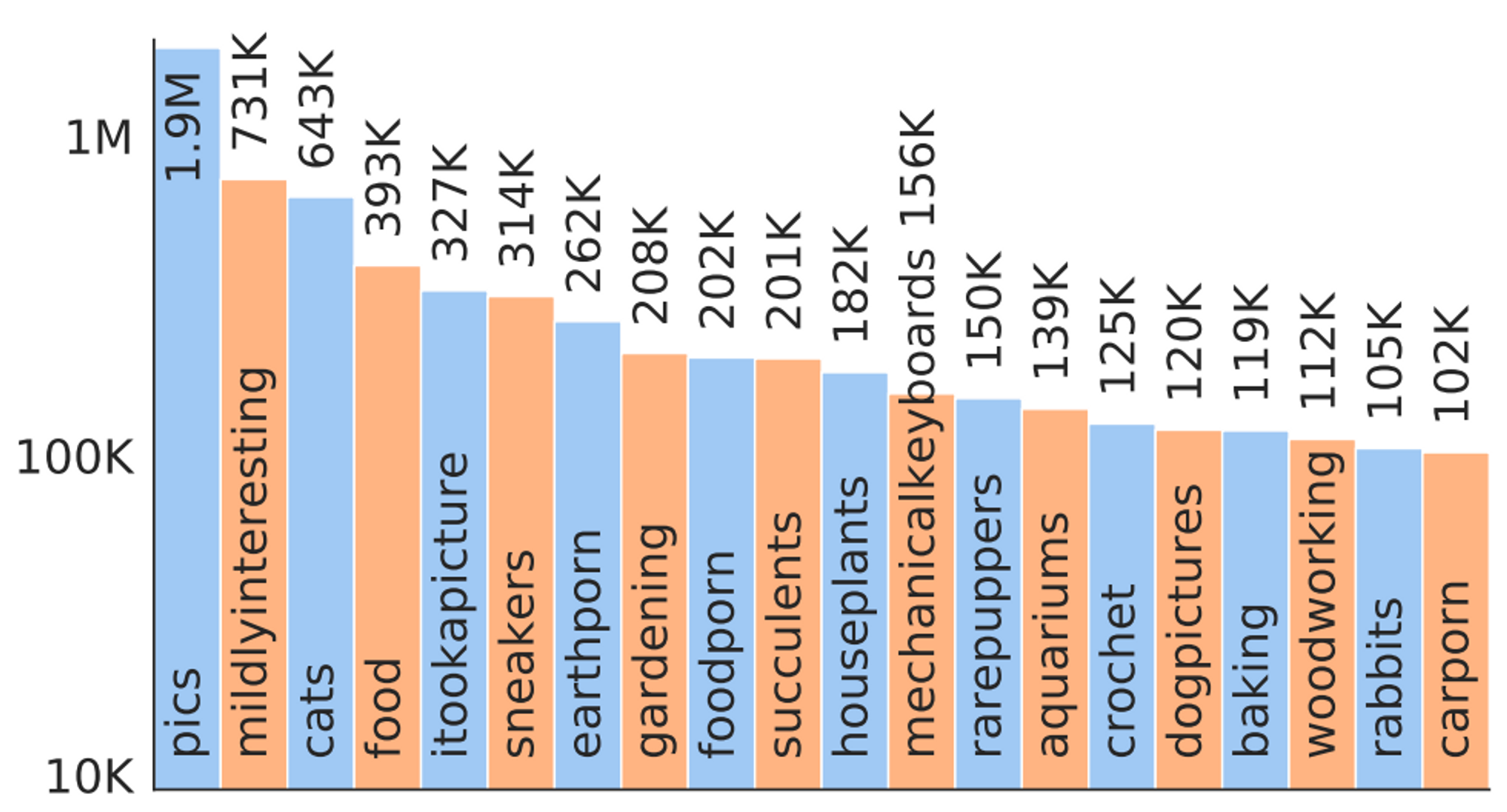
TOP20 Subreddit
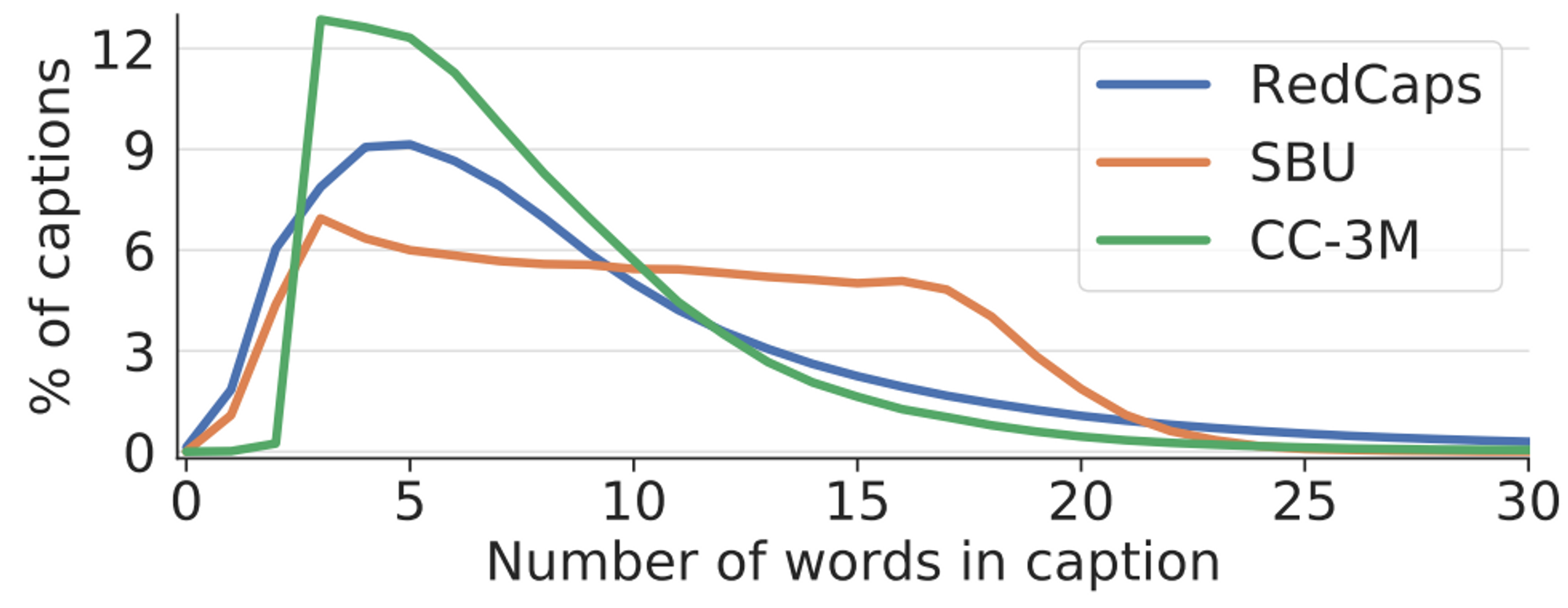
Captionの長さ
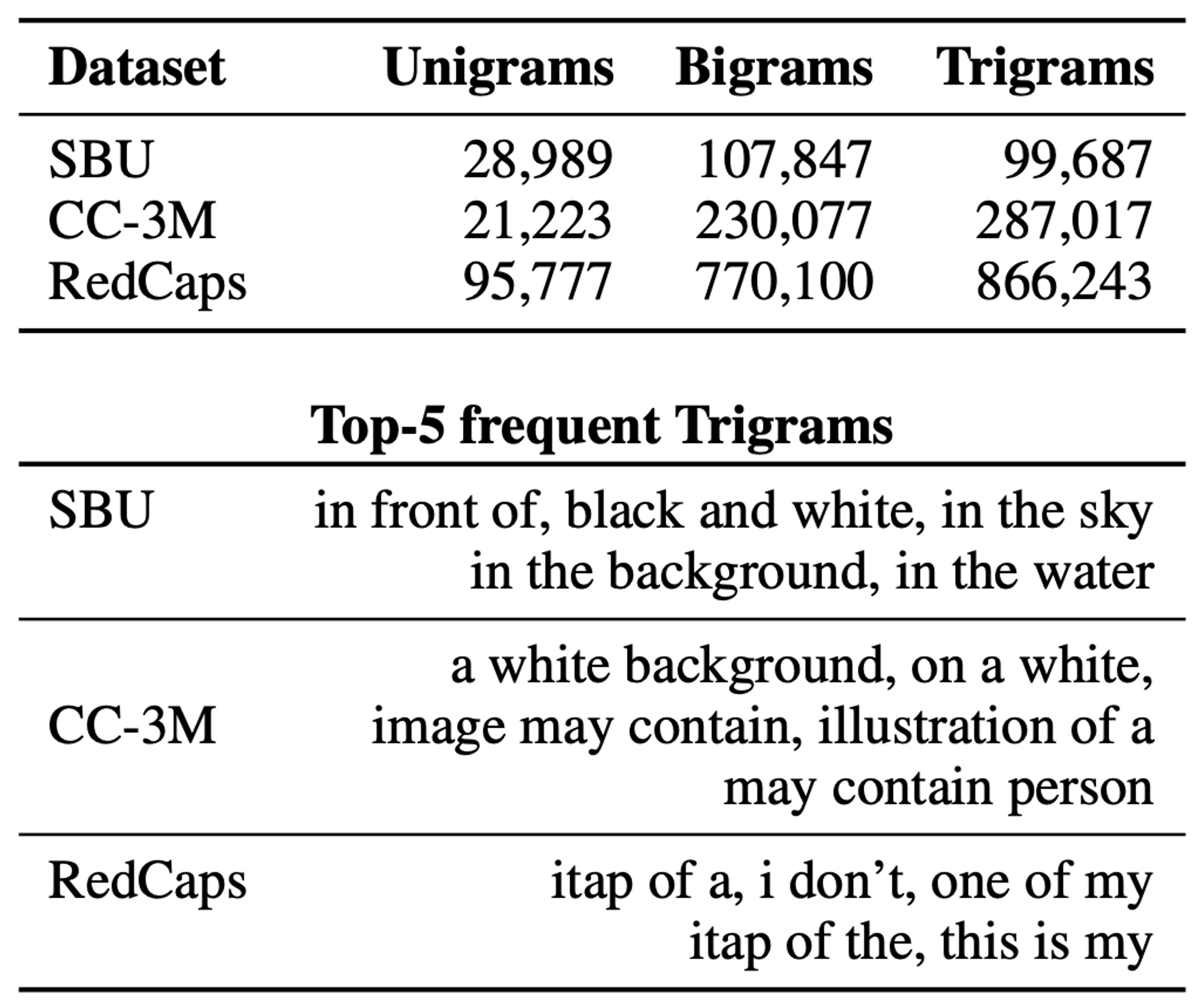
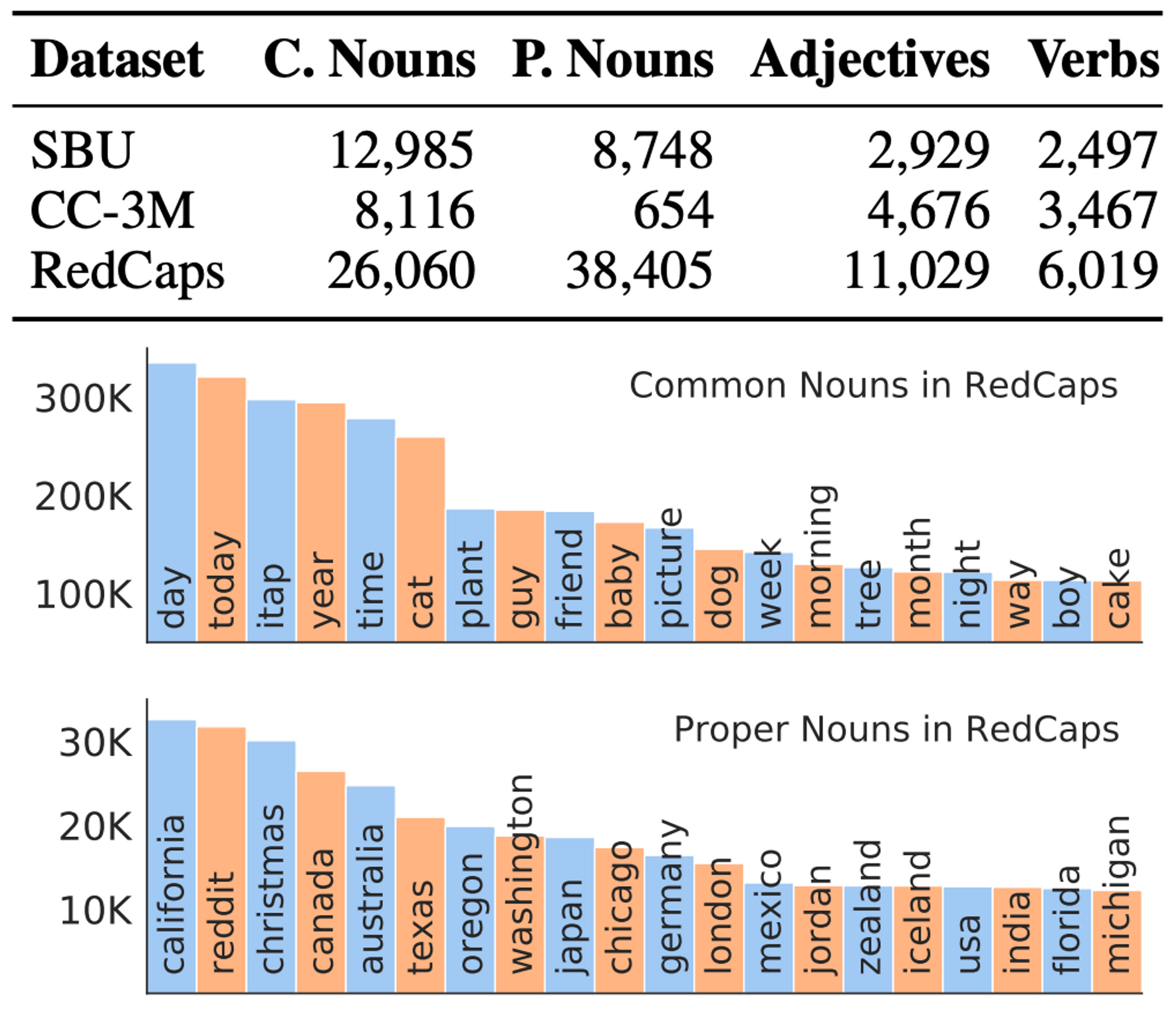
言語的多様性の比較
言語統計
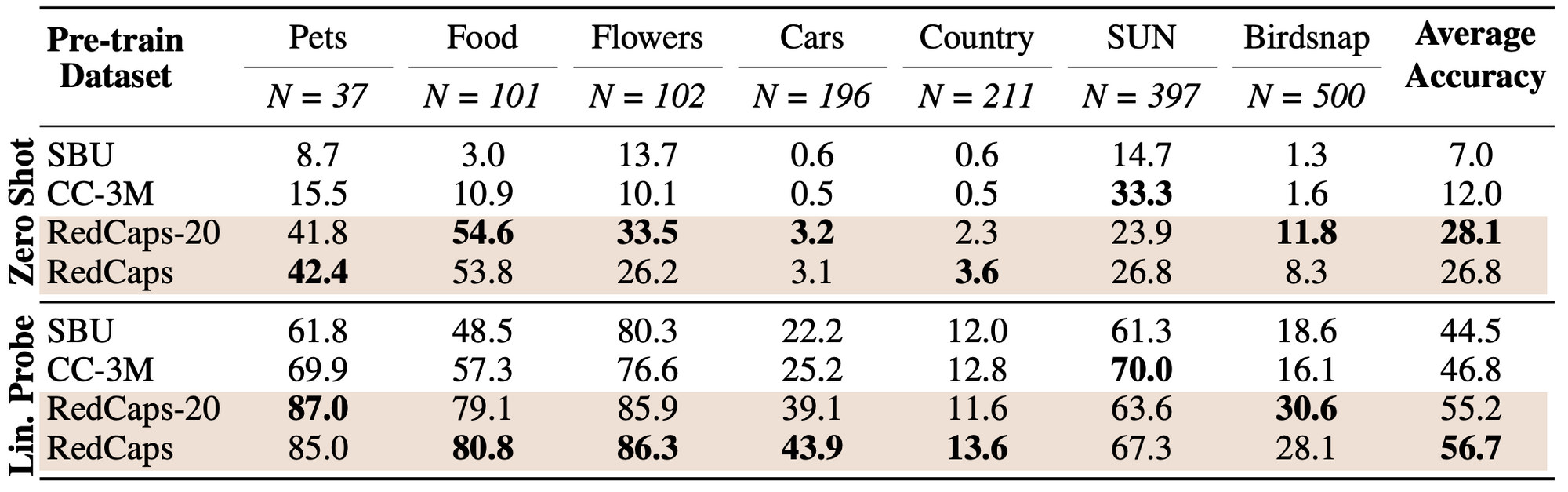
VirTex-v2を大規模データセットでPretrainしたときの、7つのデータセットのゼロショット画像分類の比較
6つのデータセットで他の大規模データセットを上回る
一覧へ戻る