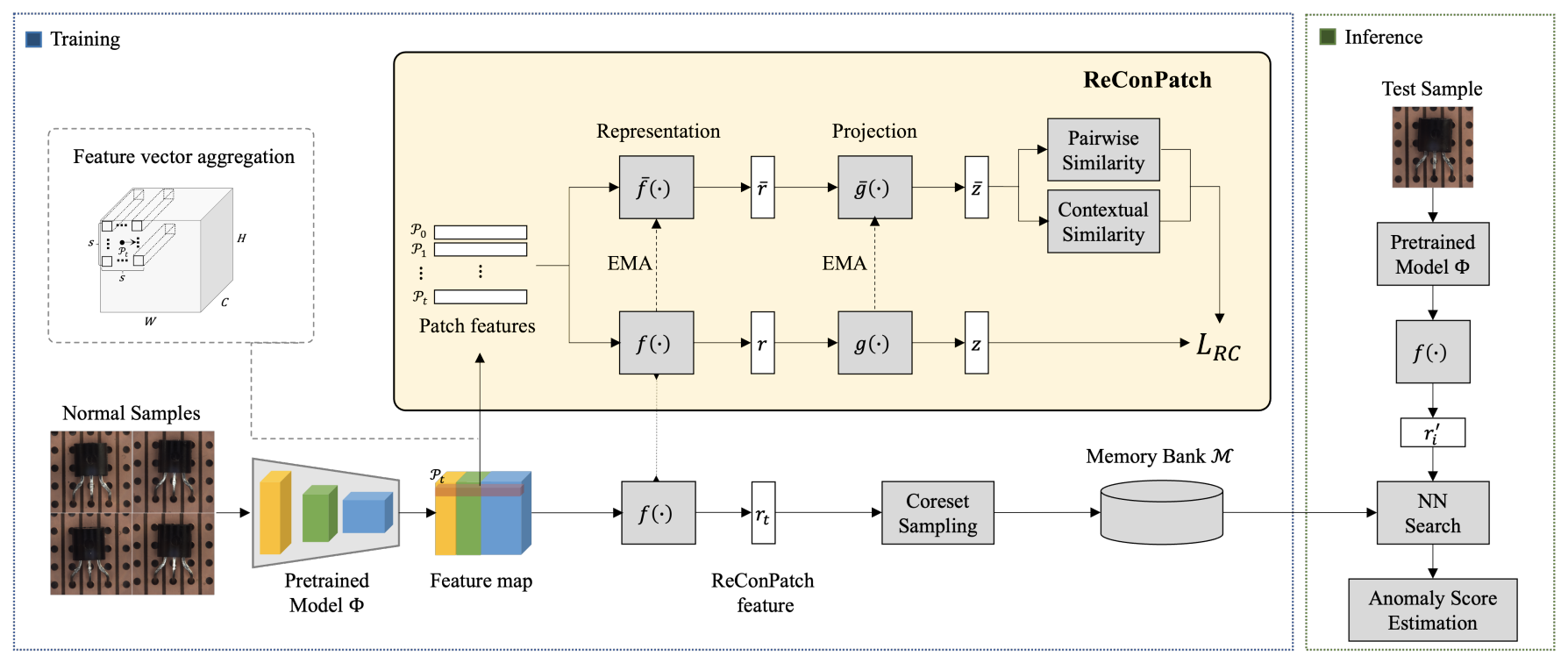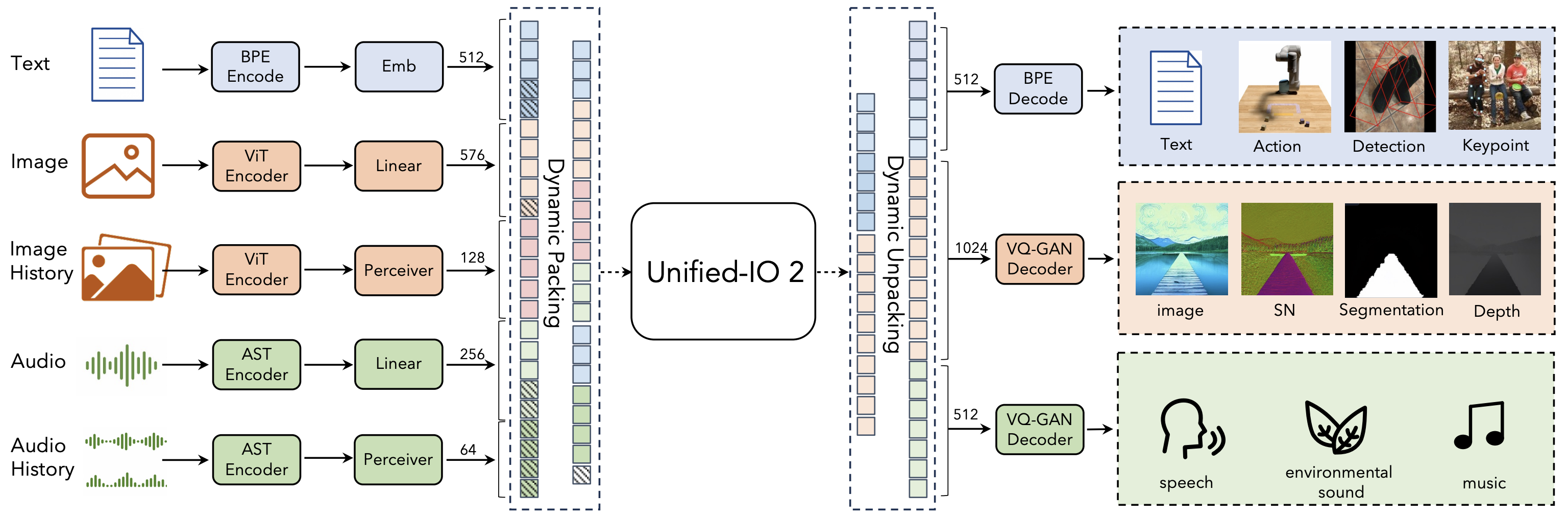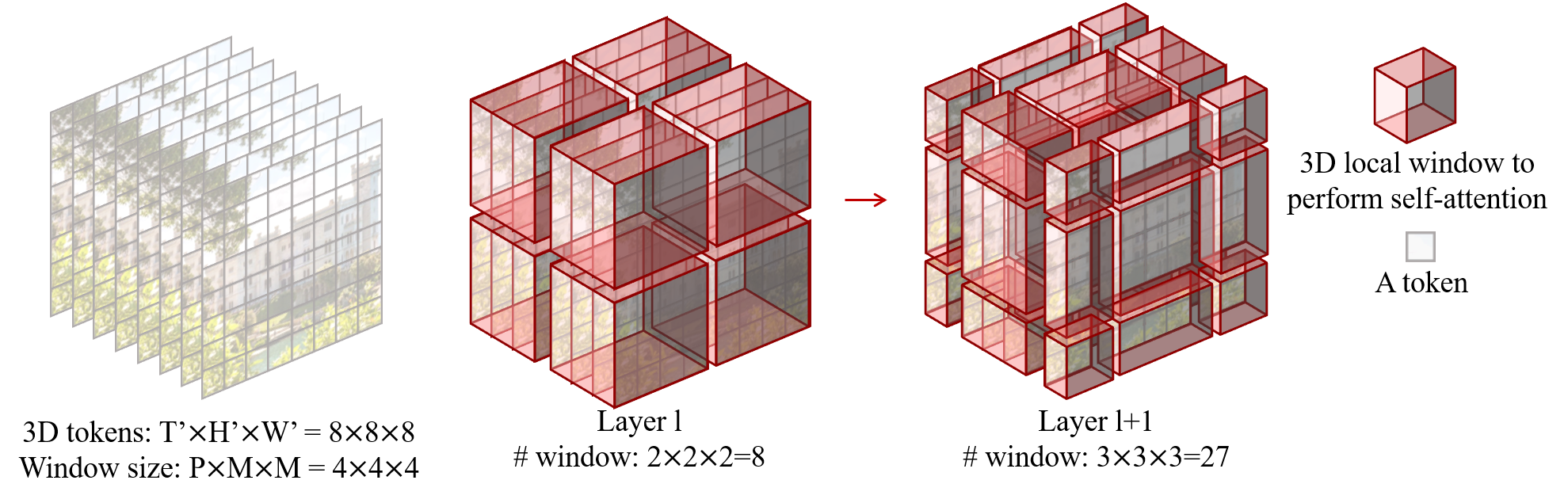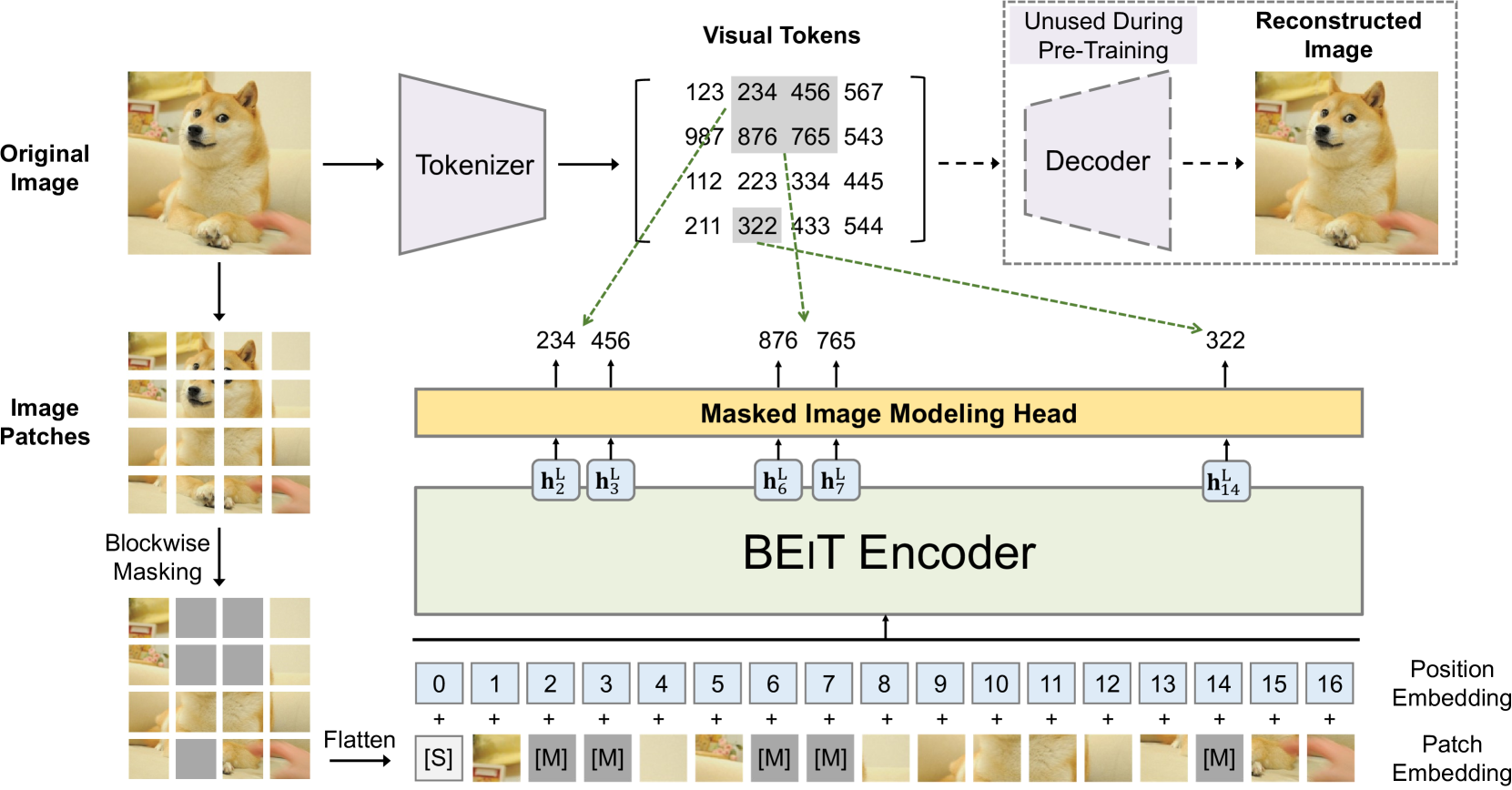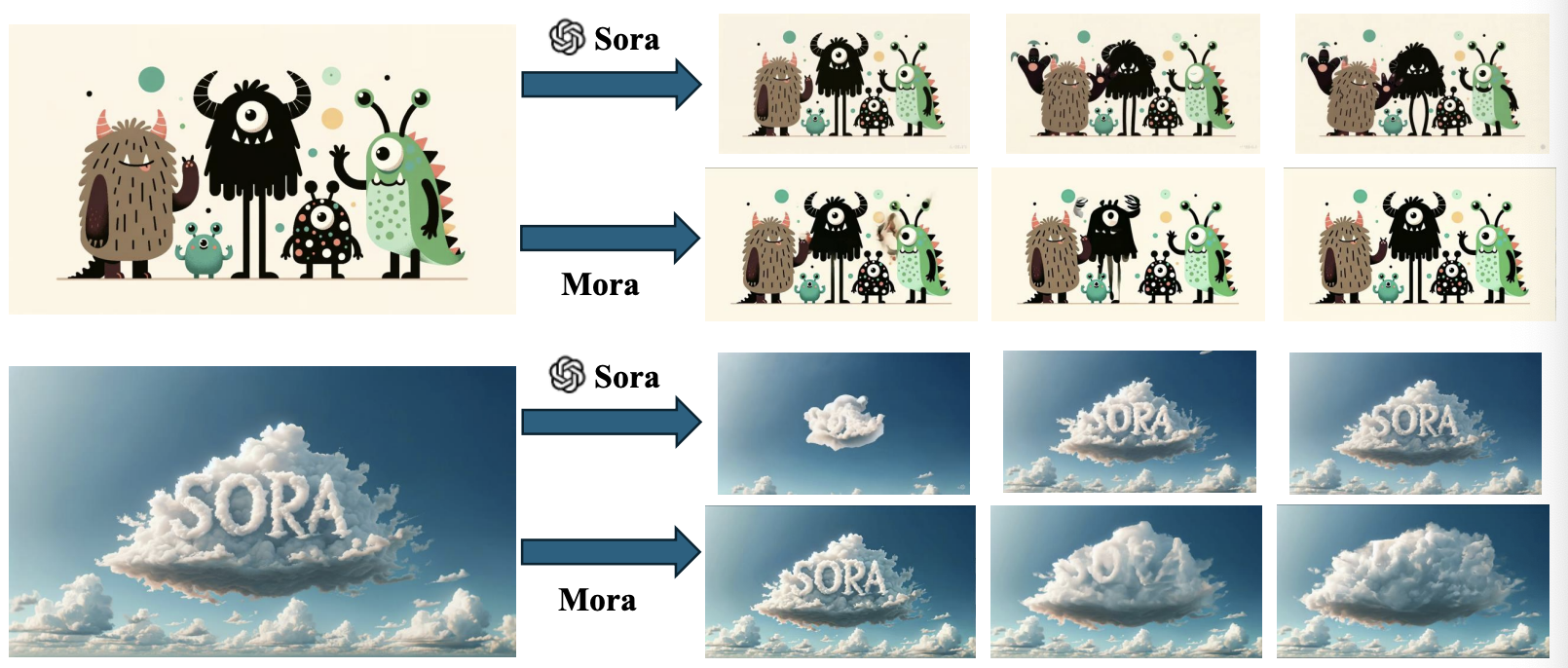
Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
- OpenAIによるSoraの影響を受け、新しいマルチエージェントフレームワークであるMoraを提案
- テキストからビデオへの生成、画像からビデオへの編集、ビデオの接続など、複数のビデオ関連タスクに対応
- 広範な実験を通じて、MoraがSoraに近い性能を示すものの、全体的な性能ギャップが存在することを確認
Mar 28, 2024 Transformer arXiv (2024)