軸屋敬介 | Keisuke Jikuya
Home
Note
Blog
Post
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action
https://unified-io-2.allenai.org/
Feb 15, 2024
Unified Frameworks, Vision and Language,
arXiv (2023)
概要
マルチモーダルモデルUNIFIED-IO 2を提案
異なるモダリティを統合するために、入出力をトークン化し、単一のEncoder Decoder Transformerモデルで意味空間を共有
モデルトレーニングの安定化のためにさまざまなアーキテクチャ改善
GRITベンチマークで最先端の性能を達成し、画像生成と理解、自然言語理解、ビデオとオーディオの理解、ロボット操作を含む35以上のベンチマークで強力な結果を達成
新規性・差分
画像、テキスト、音声、アクションを理解し、生成することができる初のマルチモーダルモデル
アイデア
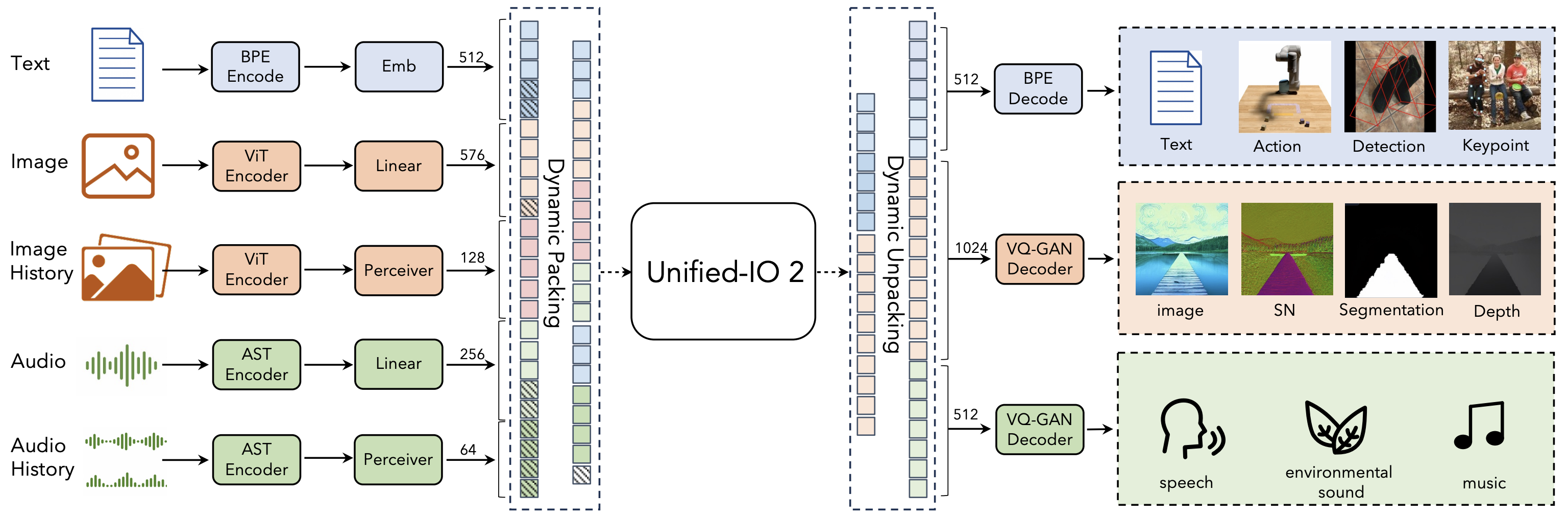
Architecture
モダリティを追加統合するにつれて学習が不安定になるため構造変更
relative positional embeddingではなく2D Rotary Embedding
dot-product attentionの前にクエリとキーにLayerNormを適用するQK Normalization
画像や音声の圧縮にperceiver resamplerを使用
perceiver resamplerにはScaled Cosine Attentionを用いる
Multimodal Mixture of Denoisers
[R] – 入力画像や音声パッチの特徴のx%をランダムにマスクし、それを再構築
[S] – 他の入力モダリティのみを条件として、ターゲットモダリティを生成
– 極端な破損
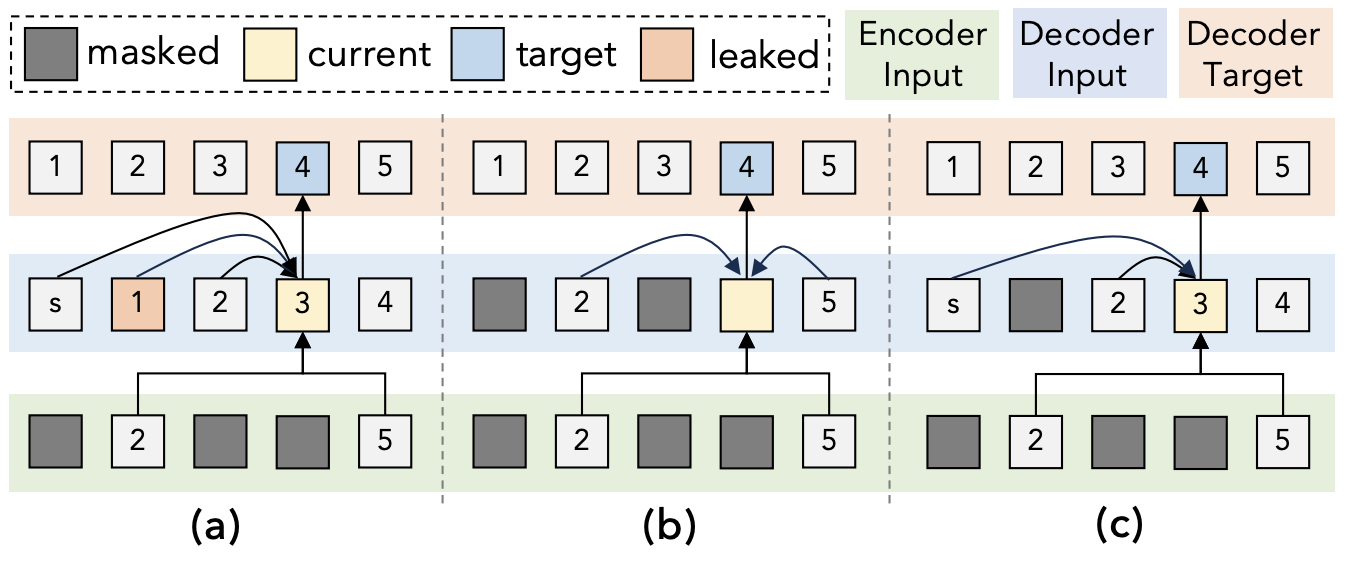
Autoregressive with Dynamic Masking
(a) autoregressive, (b) mask auto-encoder, (c) autoregressive
効率化するために、トークンの短い文章を結合して学習
Data
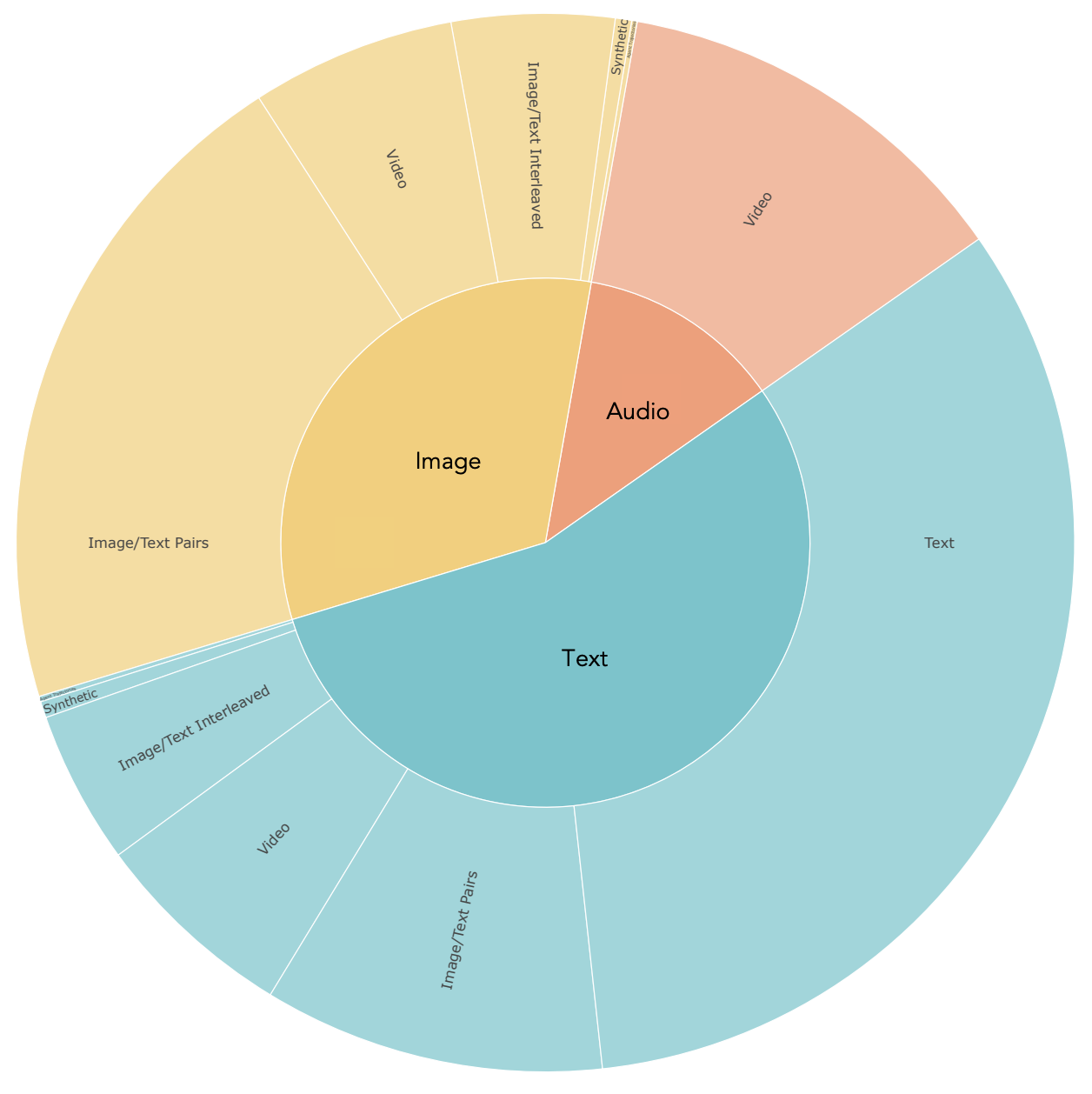
pre-training
10億の画像とテキストのペア、1兆のテキストトークン、1億8000万のビデオクリップ、1億3000万のインターリーブされた画像とテキスト、300万の3Dアセット、100万のエージェントの軌跡など
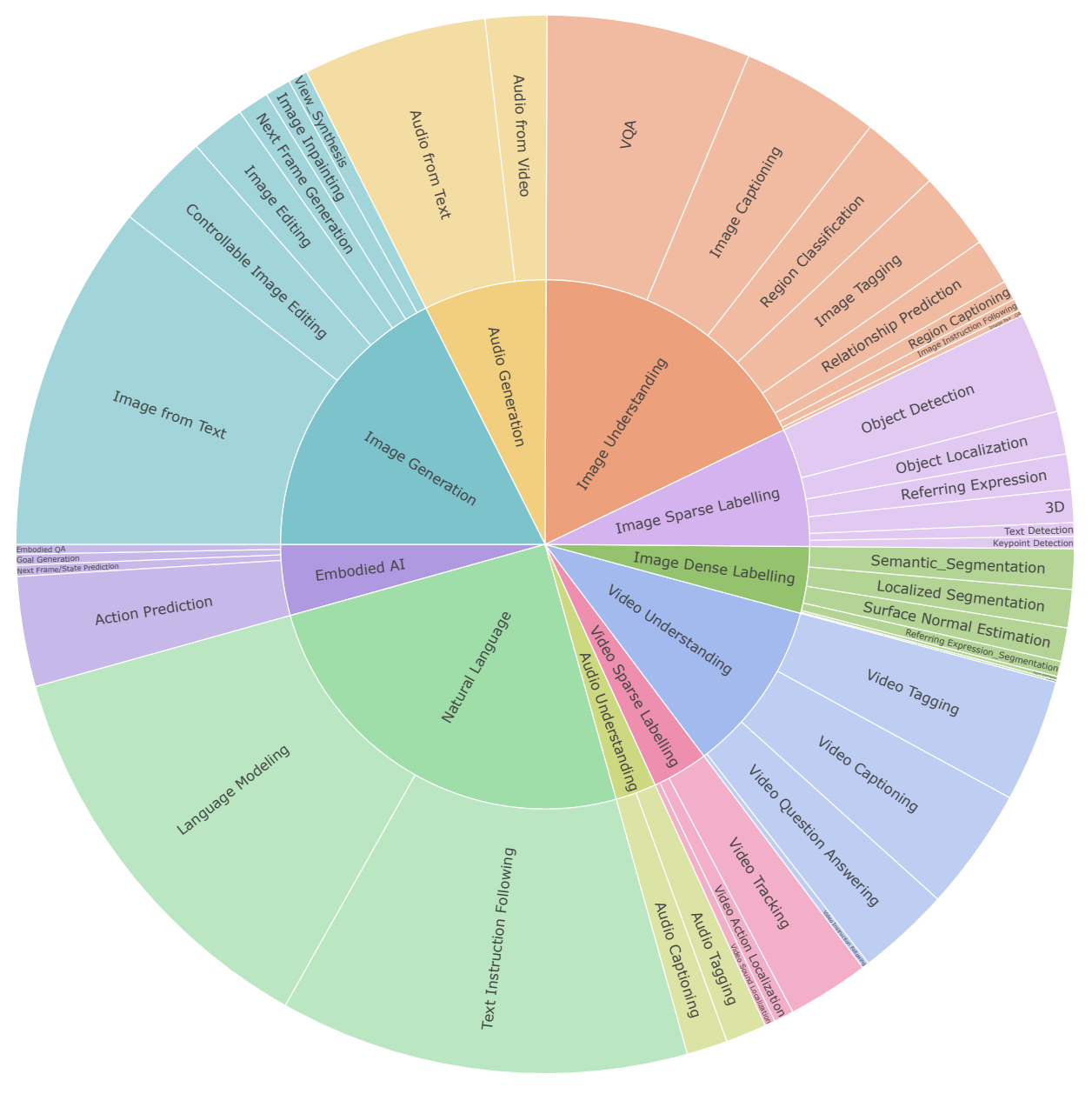
instruction tuning
視覚、言語、音声、行動など220のタスクをカバーする120以上のデータセット
結果
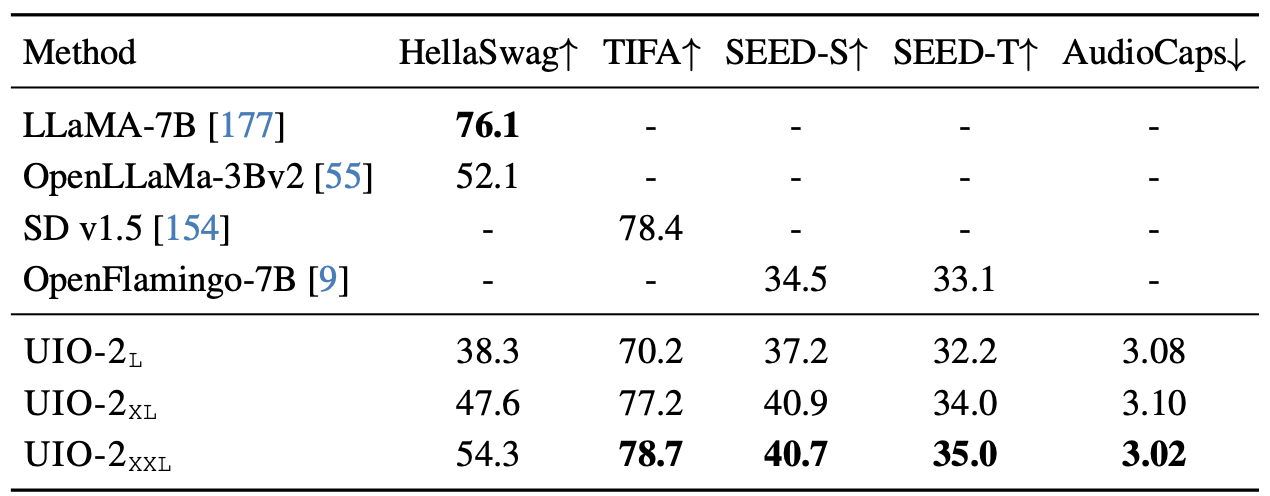
Zero-shot performance
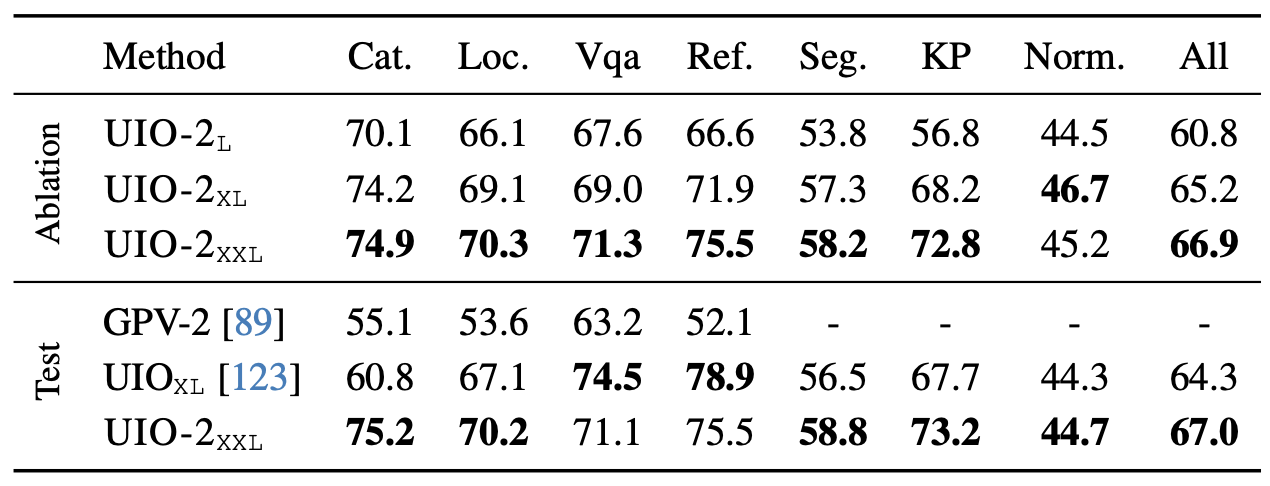
GRIT ablation and test set
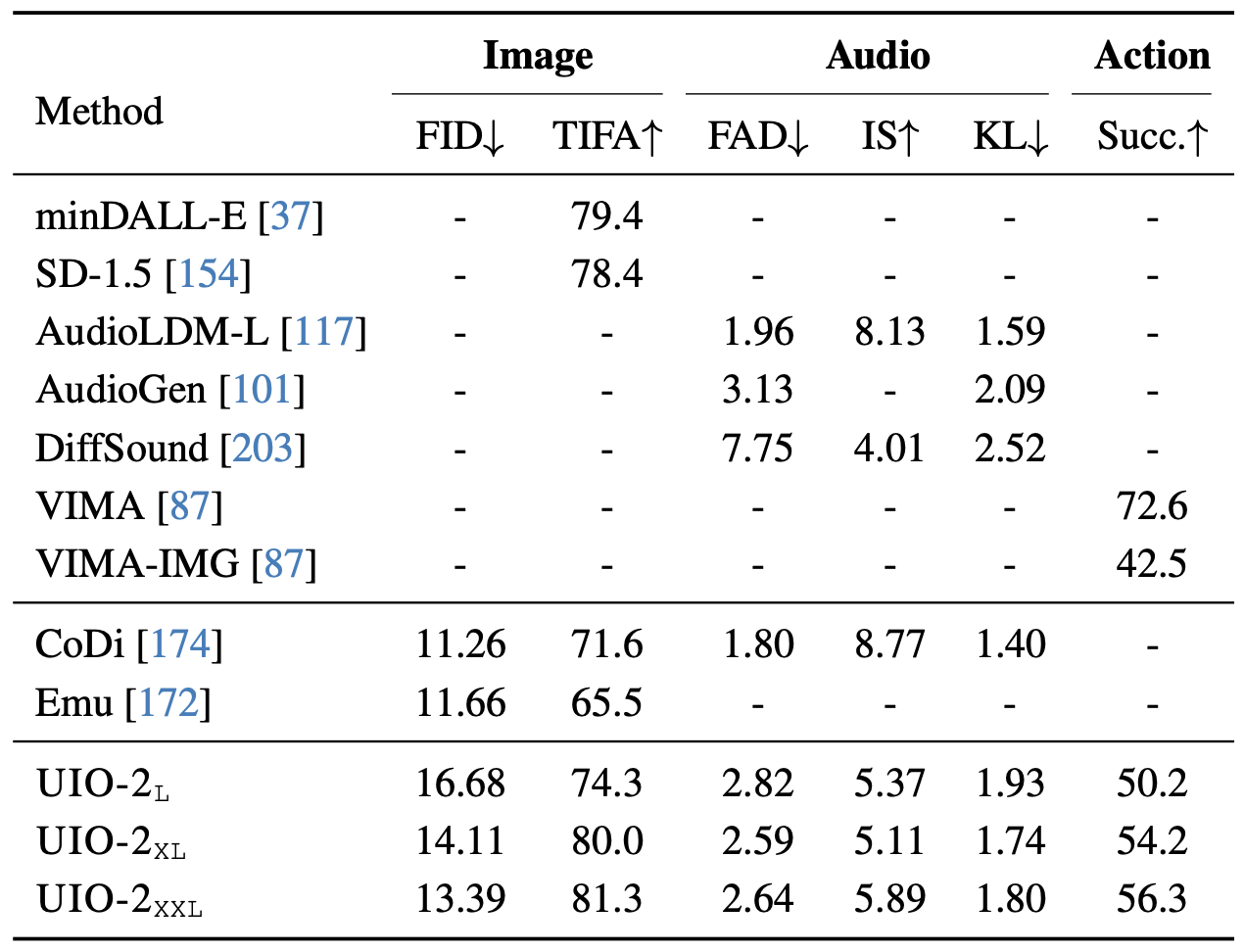
text-to-image generation
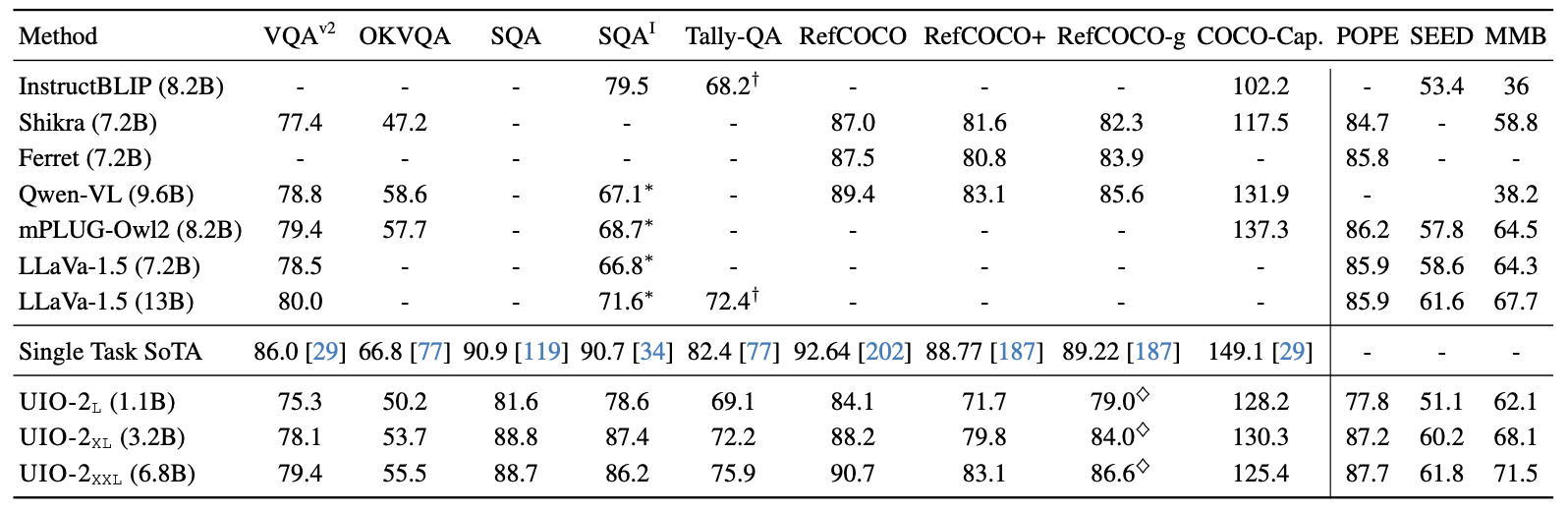
Vision-language results
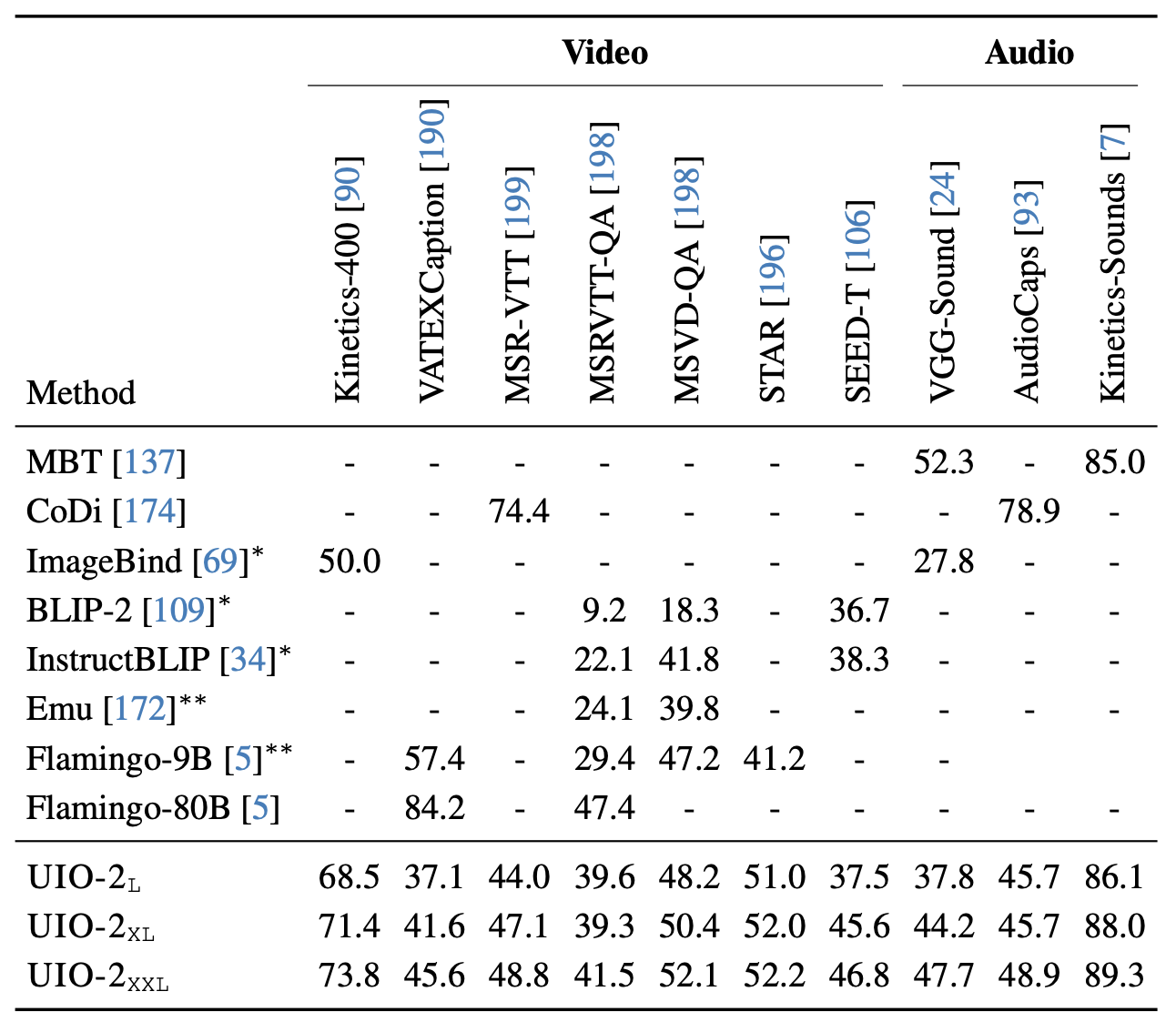
action classification, video captioning, VQA, visual comprehension, audio classification, and audio captioning
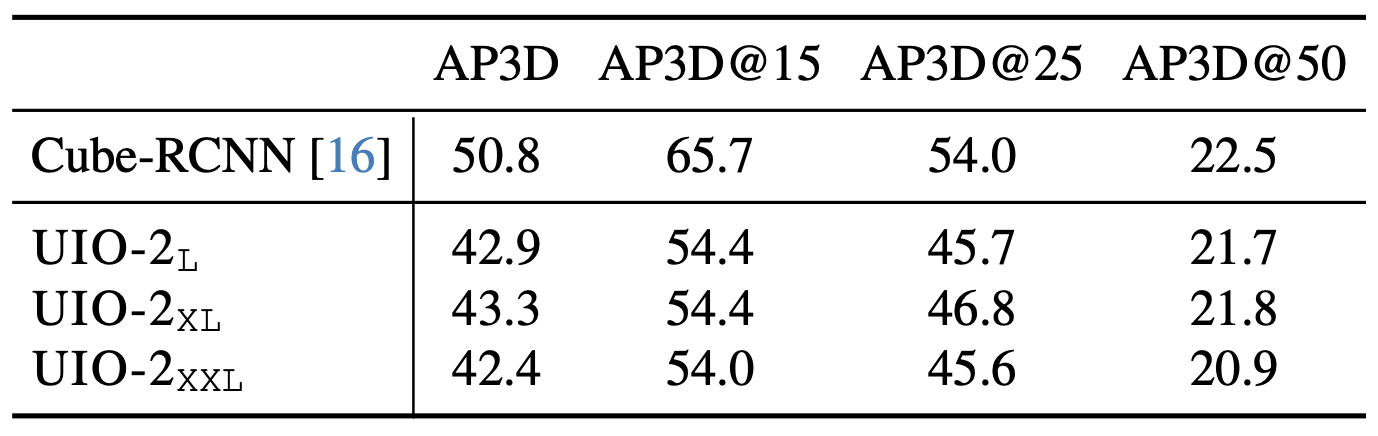
Single-object 3D detection on Objectron
一覧へ戻る