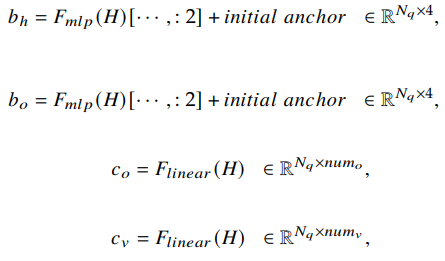FGAHOI: Fine-Grained Anchors for Human-Object Interaction Detection
FGAHOI: Fine-Grained Anchors for Human-Object Interaction Detection
https://github.com/xiaomabufei/fgahoi
Feb 21, 2023
Human-Object Interaction, FGAHOI, Fine-Grained Anchors, Noisy Background, Semantically Aligning,
arXiv (2023)
概要
- MSS, HSAM, TAMという3つから成るEnd-to-endのtransformerベースの手法(FGAHOI)を提案
- MSSは人間、物体、インタラクション領域の特徴を抽出
- HSAMとTAMは抽出された特徴量とクエリ埋め込みを
階層的な空間視点とタスク視点で順番に意味的に整列・結合
- 複雑な学習を軽減するために、新しい学習戦略Stage-wise Training Strategyを設計
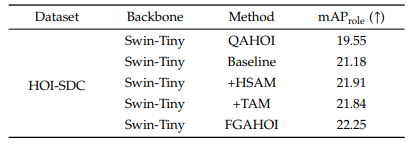
- 新規のデータセットHOI-SDCを提案
- 既存手法から大幅に精度向上
新規性・差分
- 以下の問題を低減
- 複雑な背景情報を持つ画像からいかにして重要な特徴を抽出するか
- 抽出した特徴量とクエリ埋め込みをどのように意味的に整合させるか
アイデア
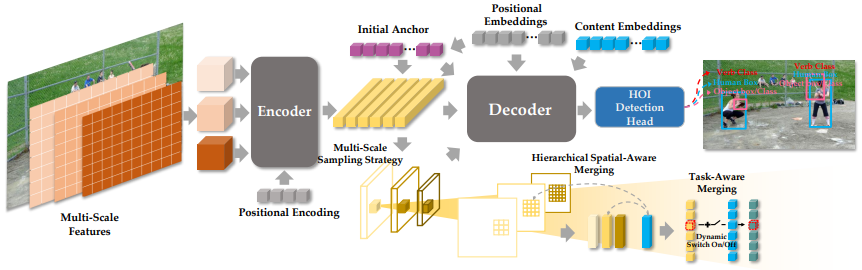
- 全体構造
- Multi-Scale Features Extractor
-
\[M = F_{encoder}(F_{flatten}(\phi(x)),p,s,r,l) \in \mathbb{R}^{N_s \times C_d}\]
- 事前学習済みBackbone(Swin Transformer)でマルチスケール特徴を抽出
- transformer encoderで符号化して意味特徴量を得る
- Decoder
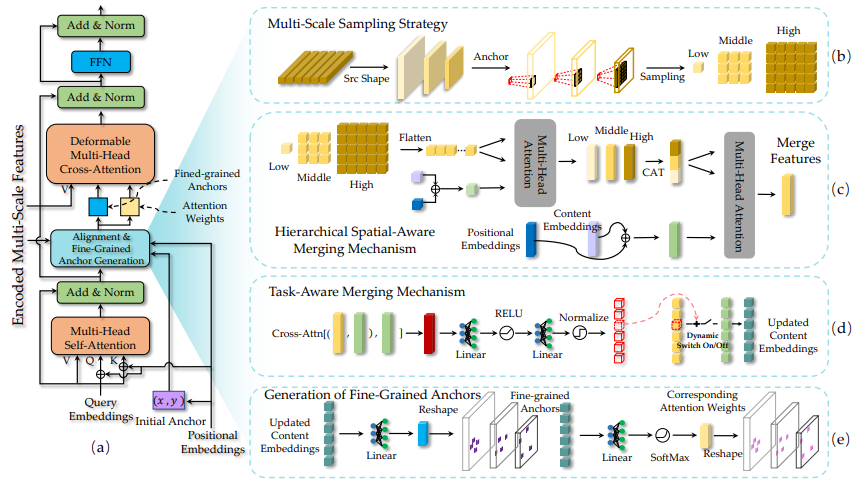
- Multi-Scale Sampling (MSS)
-
\[x^i_s = F_{sample} (reshape(M)^i, A, size^i, bilinear)\]
- transformer encoderの特徴を元の形状に整形
- 小さなインスタンスを検出する浅い特徴量では小さくサンプリング
- 大きなインスタンスを検出する深い特徴量では大きくサンプリング
- Hierarchical Spatial-Aware Merging (HSAM)
- サンプリングした各層の特徴をKeyとValue,位置PとコンテキストCをQueryとしてMHA
-
\[C_u = C + F_{MHA}\big((C+P)W^q, (C+P)W^k, CW^v \big)\]
-
\[x^u_m = F_{concat} (\mathrm{head}_1, ... , \mathrm{head}_h) W^O\]
-
\[\mathrm{where} \space \mathrm{head}_n = \mathrm{Softmax\big(\frac{(C_u W^q_n)\cdot(x^i_s W^k_n)^T}{\sqrt{d_k}}\big)} (x^i_s W^v_n)\]
- 特徴内Attention
- MHAに通した各層の特徴をConcat
-
\[X_m = F_{concat} ({x^i_m}_{i=0,1,2}) \in \mathbb{R}^{B \times N_q \times N_L \times N_{hd}}\]
- Concatした特徴をKeyとValue,位置PとコンテキストCをQueryとしてMHA
-
\[X_u = F_{concat} (\mathrm{head}_1, ... , \mathrm{head}_h) W^O\]
-
\[\mathrm{where} \space \mathrm{head}_n = \mathrm{Softmax\big(\frac{(C_u W^q_n)\cdot(X_m W^k_n)^T}{\sqrt{d_k}}\big)} (X W^v_n)\]
- 特徴間Attention
- Task-Aware Mergin (TAM)
- HSAMの出力特徴とコンテンツ埋め込みを融合しCross Attention
-
\[X = F_{stack} (C_u, X_u) \in \mathbb{R}^{B \times N_q \times (2 \times N_{hd})}\]
-
\[X_{switch} = F_{stack} (\mathrm{head}_1, ... , \mathrm{head}_h) W^O\]
-
\[\mathrm{where} \space \mathrm{head}_n = \mathrm{Softmax\big(\frac{(C_u W^q_n)\cdot(X W^k_n)^T}{\sqrt{d_k}}\big)} (X W^v_n)\]
- 適切なチャンネルを選択する動的なスイッチを生成
-
\[Switch^{\gamma} = F_{normalize}(D_{mlp}(X_{switch}))^{\gamma} \in \mathbb{R}^{B \times N_q \times 2 \times 2}\]
- HSAMの出力特徴に対し,スイッチで一部を選択
-
\[U^{\gamma} = F_{Max} \{Switch^{\gamma}_{i,0} \odot X^{\gamma}_u + Switch^{\gamma}_{i,1}\}_{i=0,1} + C^{\gamma}_u\]
- Decoding with Fine-Grained Anchor
- 内容埋め込みを線形層、リシェイプ、SoftMaxに通すことで
Cross AttentionのQueryとなるAnchorとKeyとなるAttention weightを生成
- HOI Detection Head
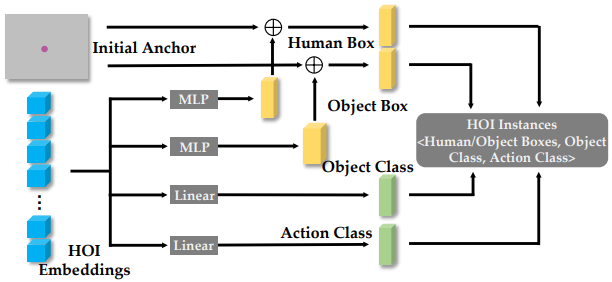
- HOI埋め込みと初期アンカーを利用して,人間と物体のBB・物体のクラス・インタラクションを予測
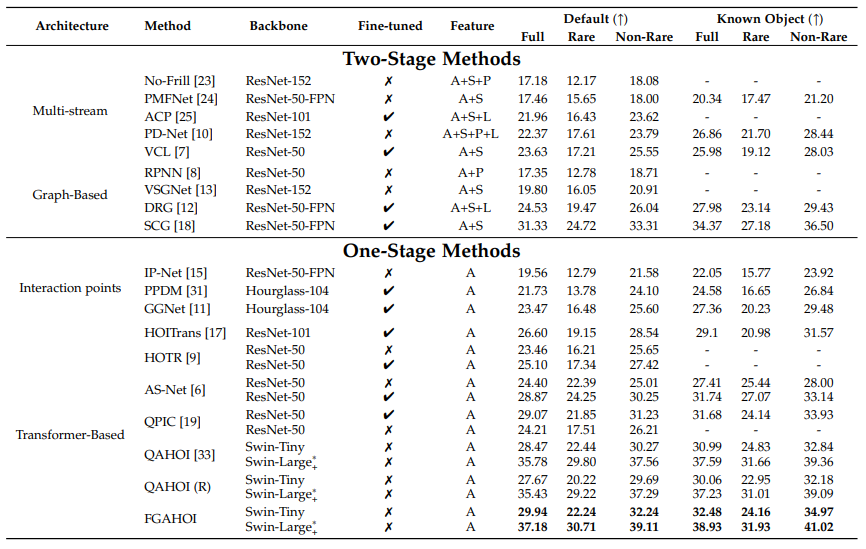
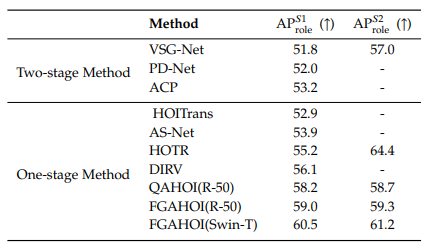
結果