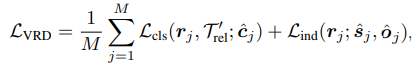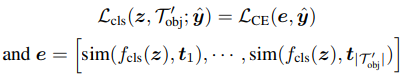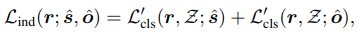Unified Visual Relationship Detection with Vision and Language Models
Unified Visual Relationship Detection with Vision and Language Models
https://arxiv.org/abs/2303.08998v1arXic
Mar 28, 2023
HOI, Transformer, Vision and Language,
arXiv (2023)
概要
- Visual Relationship Detection(VRD)では、1つのデータセットから学習するため、画像ドメインと語彙に制約があり、汎用性と拡張性に限界がある
- Vision&Languageモデルを活用し、複数のデータセットを統一するフレームワークUniVRDを提案
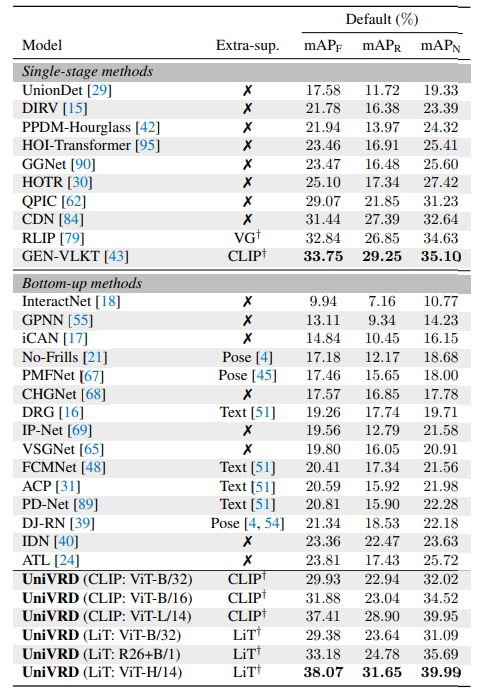
- HICO-DETにおいて60%アップの38.07mAP
新規性・差分
- Vision&Languageモデルによる複数データセットの統一
- モデルや損失、訓練方法の改善
アイデア
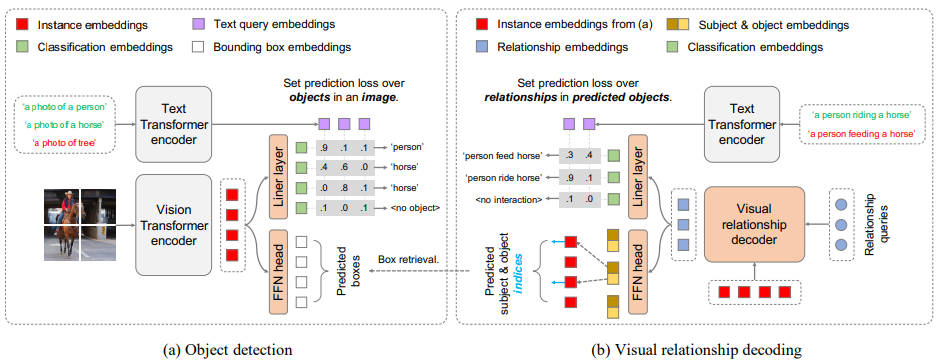
- 物体検出器
- CLIPなどと同様にテキストEncoderとしてtransformer,画像EncoderとしてViTを使用
- 画像Encoderは、プーリング層と最終層を削除して、トークン埋め込み層を追加する
- トークン埋め込みを線形層に通すことで分類埋め込みを,FFNに通すことでBBを得る
- Encoderのみで動作するため、知識抽出や事前学習を必要としない
- Relationship Decoder
- 入力をEncoderのトークン埋め込みと関係クエリ(学習)として,関係埋め込みを得る
- 関係埋め込みを線形層に通すことで関係分類埋め込みを,FFNに通すことで主語と目的後のインデックスを得る
- 分類用テキスト埋め込み
- 物体/関係の分類では整数値ではなく,テキスト埋め込みを使用
- 物体の分類:「person」を「a photo of person」にしてテキストEncoderへ
- 関係の分類:「person(主語), ride(述語), horse(目的)」を「a person riding a orse」にしてテキストEncoderへ
- 検出器はテキスト埋め込みに対してクラス確率を予測する
- データ拡張
- モザイク
- 画像をグリッドにすることで、モデルが見るスケールの幅を広げる
- テキストプロンプティング
- CLIPのように、プロンプトテンプレートを使用
- 物体:「a photo of <object>」
- 関係:「a <subject> <predicate>ing a <object>」
- 学習
- 物体検出とDecoderを順番に学習したほうが安定的かつ効果的
- Decoderの学習時に学習データが限られている場合は物体検出器を凍結したほうがよい
- Loss関数
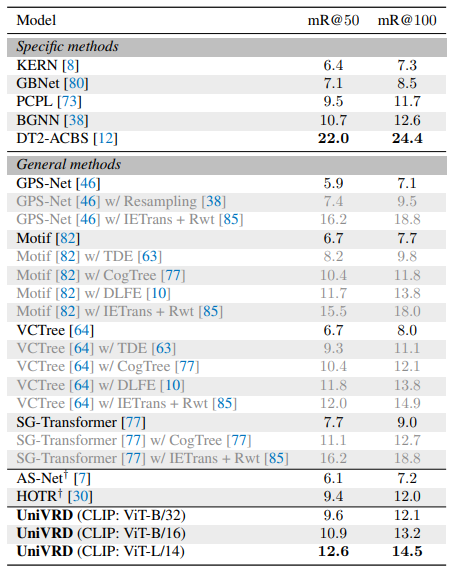
結果
- HOI(Himan-Object Interaction)
- SGG(Scene Graph Generation)