ViPLO: Vision Transformer based Pose-Conditioned Self-Loop Graph for Human-Object Interaction Detection
ViPLO: Vision Transformer based Pose-Conditioned Self-Loop Graph for Human-Object Interaction Detection
https://arxiv.org/abs/2304.08114v1
May 9, 2023
Human-Object Interaction, CLIP, ViT,
CVPR (2023)
概要
- MOAモジュールと姿勢条件付きグラフの2段階のHOI検出器ViPROを提案
- MOAモジュールにより量子化問題に対処し、ViTを特徴抽出器として利用
- 人間のプロセスに触発された姿勢条件付きグラフにより、人間の姿勢から豊富な情報を利用
- 1段階法と比べて、低複雑性と実世界シナリオへの適用性の利点がある
新規性・差分
アイデア
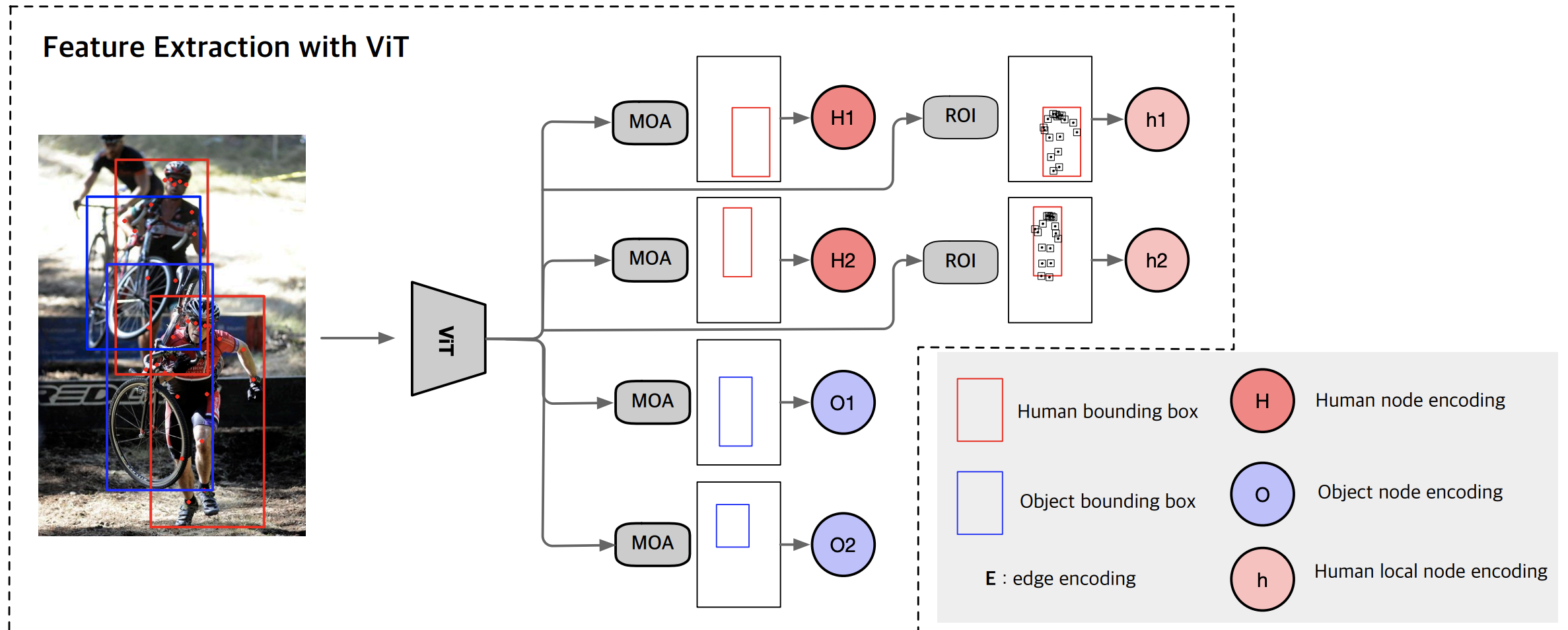
- ViT Backboneを使用した特徴抽出
- Faster R-CNNを使用して、画像から人間とオブジェクトを検出
- 特徴抽出にResNetではなくViTを使用
- ViTに対応するためにMOAモジュールを導入
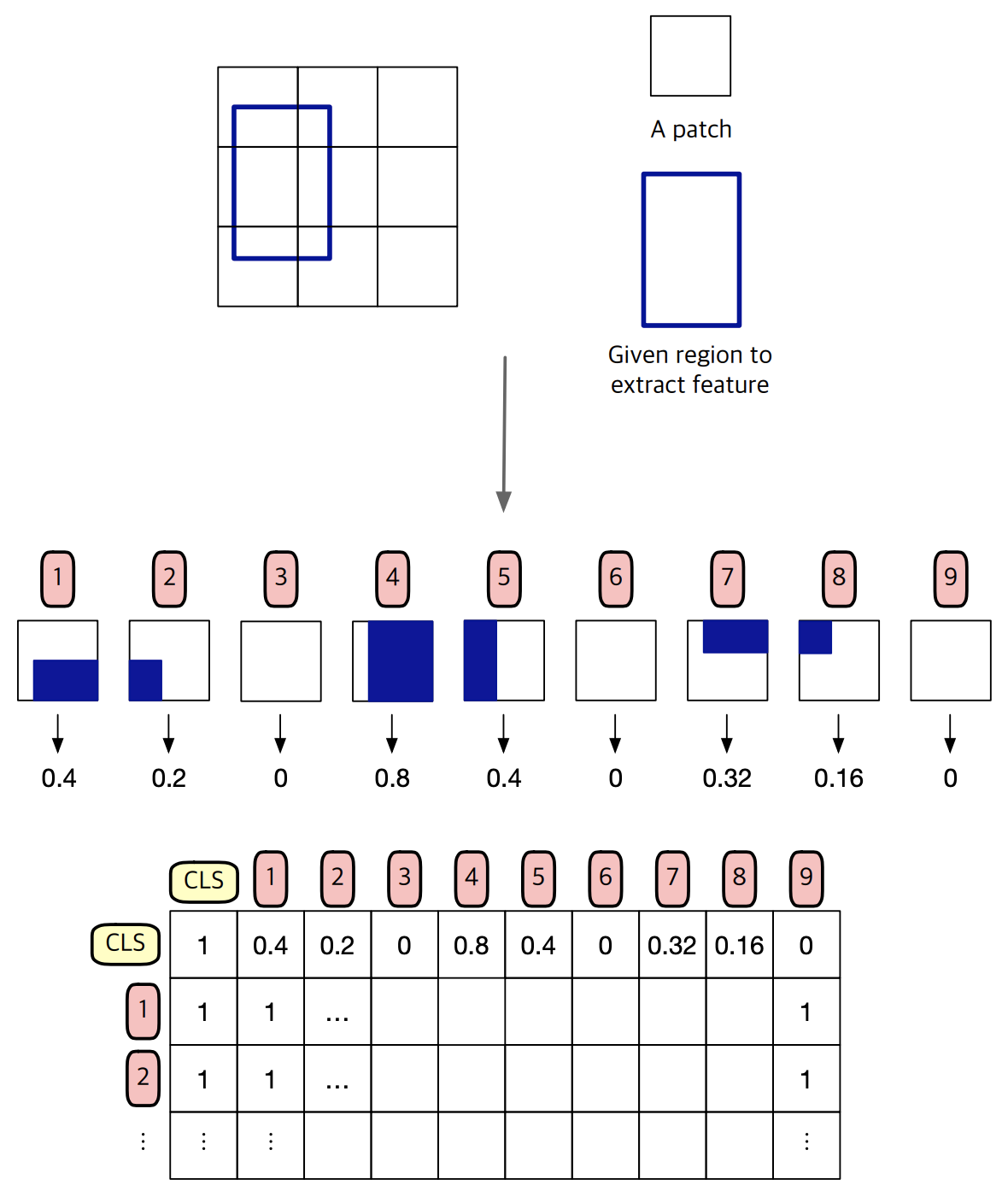
- ViT Backboneの出力特徴から、人間とオブジェクトの特徴を抽出する
- パッチと領域の重なりを利用して、Attention MAPを作成
- MOAモジュールによりHOI検出で大きなパフォーマンスの向上
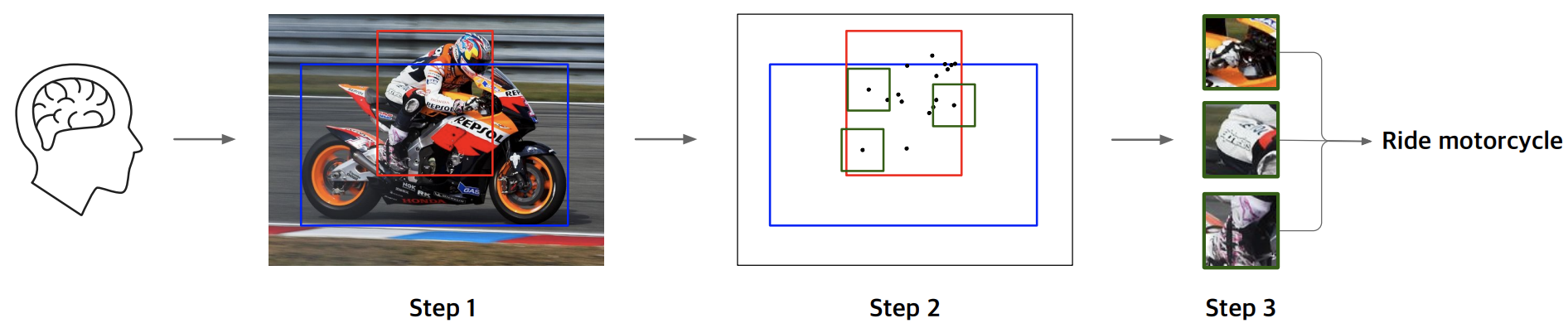
- 姿勢条件付きグラフニューラルネットワーク
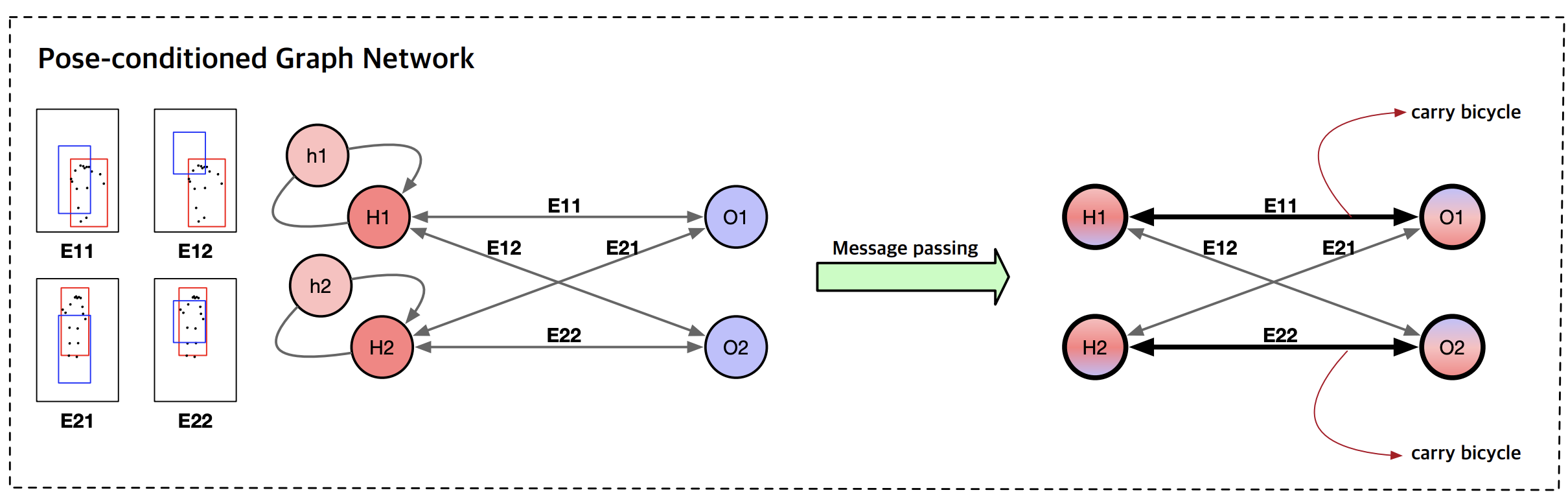
- 人間とオブジェクト間のインタラクションを検出するために使用
- 空間条件付きグラフ(SCG)ベース
- ResNetとROIAlignを使用して抽出した特徴でノードを初期化
- エッジエンコーディングを人間とオブジェクトの2つの境界ボックスの空間情報に基づく特徴で初期化
- エッジエンコーディングに条件付けられたノード間で双方向メッセージパッシングを実行
- 更新されたノードエンコーディングとエッジエンコーディングはHOIの分類に使用
- 姿勢認識エッジエンコーディング
- 空間情報だけでなく人間の姿勢情報に基づいて初期化する
- CGと同様にペアワイズ空間特徴(つまり、クエリ)を計算
- 各関節の座標と関節から、ペアワイズ関節特徴(つまり、キー)を計算
- クエリとキーの内積によって各人間の関節の注意スコアを計算
- メッセージパッシングと姿勢
- 各人間の関節のローカル領域ボックスのViT出力をUnFlattenしてROIAlignを適用してローカル特徴を抽出
- 抽出特徴を人間のノードエンコーディングを更新するために使用
結果
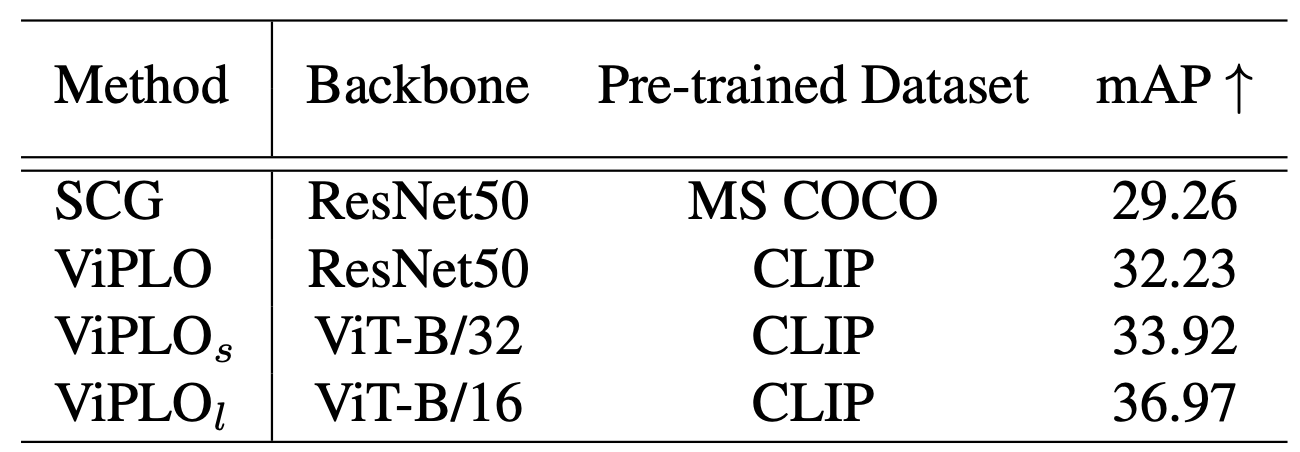
- HICO-DET & V-COCO
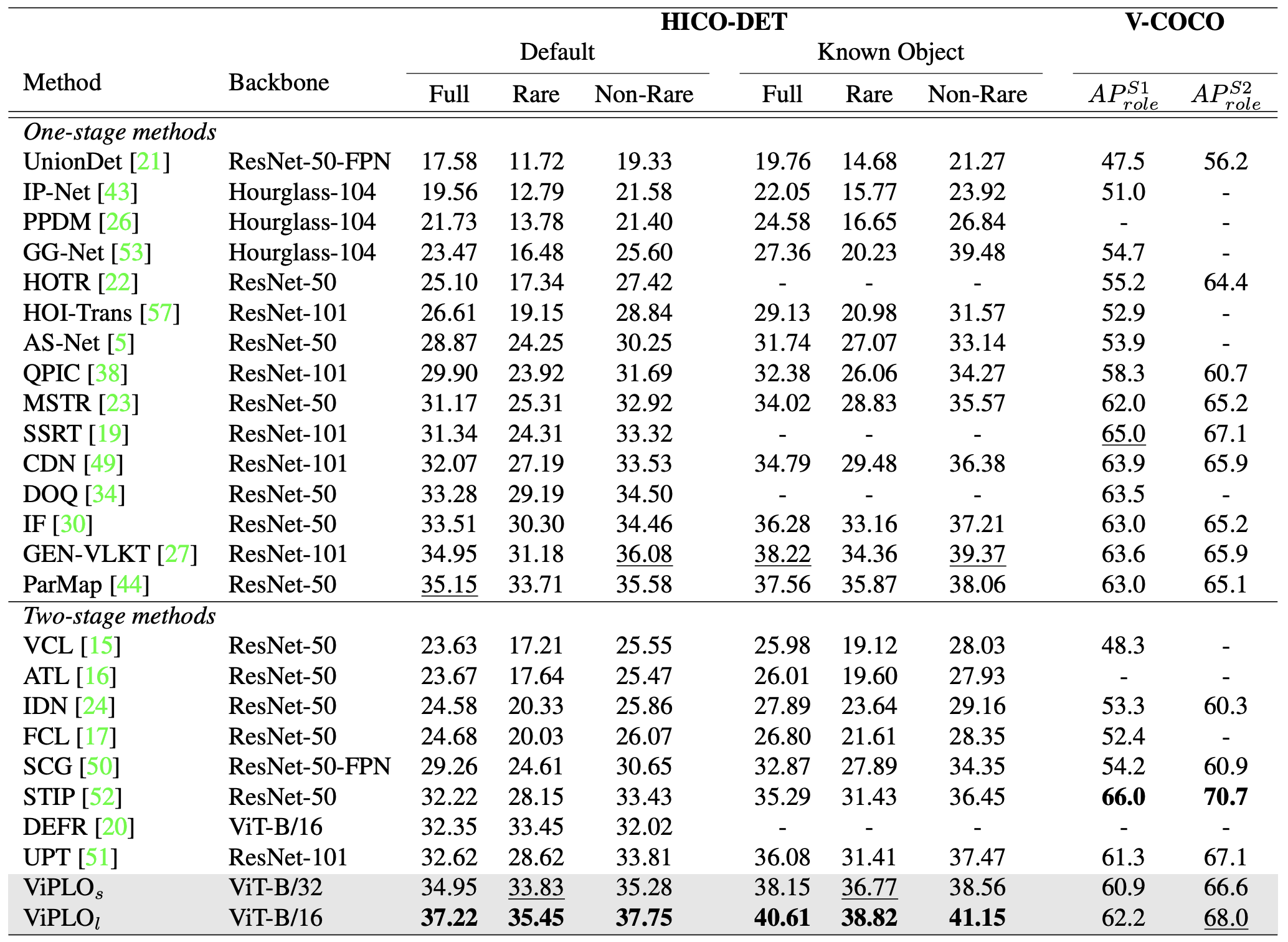
- HICOで2.07 mAP向上
- SCGとの比較

- left: ViPLO, right: SCG
- CLIP重みの有効性