軸屋敬介 | Keisuke Jikuya
Home
Note
Blog
Post
pixelNeRF: Neural Radiance Fields from One or Few Images
pixelNeRF: Neural Radiance Fields from One or Few Images
https://alexyu.net/pixelnerf/
May 12, 2022
NeRF, Sparse Views, Pretrained,
CVPR (2020)
概要
1枚または数枚の画像からNeRFを生成するpixelNeRFを提案
NeRFは入力画像が少ない場合 、汎化できず、性能が低下する
それに対し、pixelNeRFではCNNで抽出した特徴量で条件付けることで解決した
アイデア
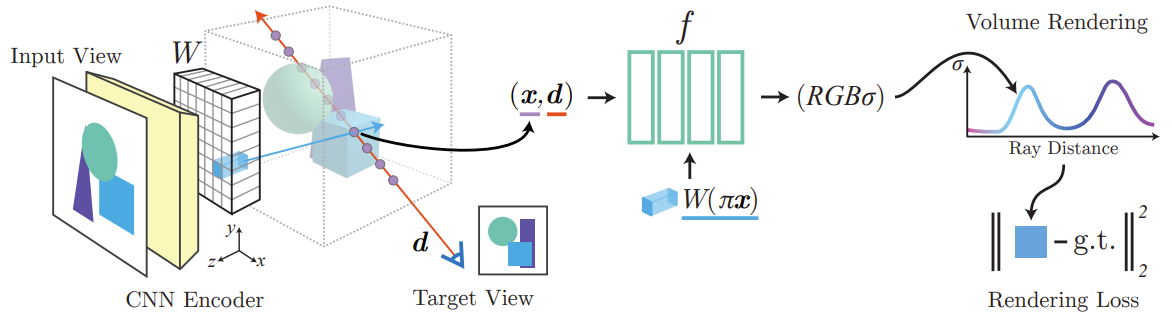
入力画像が1つの場合
入力画像$I$をCNN Encoderに通し特徴量$W=E(I)$を取得
ターゲットカメラ光線上の点xを画像平面上に投影した座標$\pi(x)$の特徴量$W(\pi(x))$を取得
$x$の位置符号化$\gamma(x)$と視線方向$d$と特徴量$W(\pi(x))$を
NeRFニューラルネットワーク $f()$に入力することで$x$での色と密度を取得
$(\sigma,c) = f(\gamma(x),d; W(\pi(x)))$
ボリュームレンダリングによってターゲット画像を生成
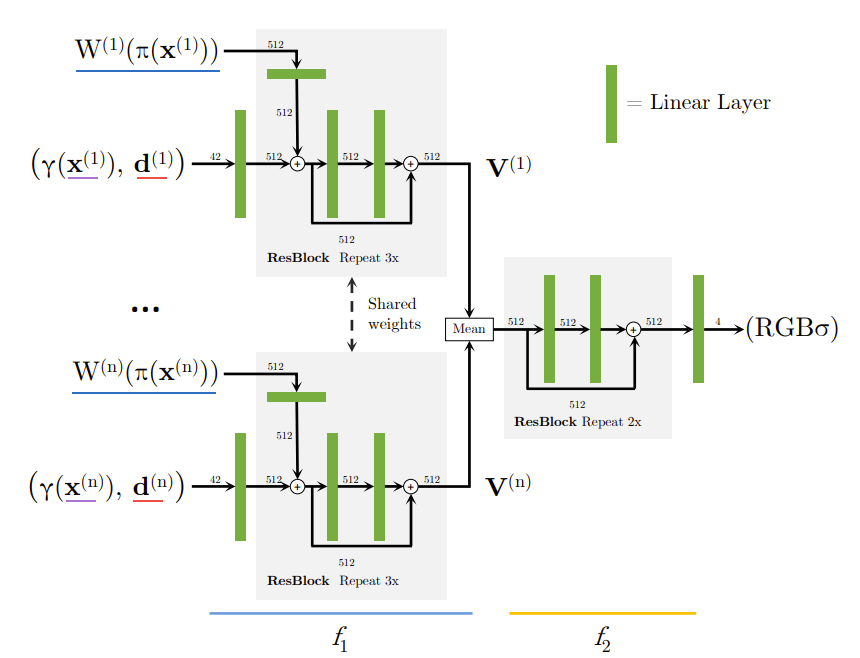
入力画像が数枚の場合
i番目の入力画像に対し,ワールド座標からカメラ座標へ変換した$x^{(i)}$と$d^{(i)}$について 1つの場合と同様にしてニューラルネットワーク $f_1()$に入力することで 中間ベクトル$V^{(i)}$を取得 $V^{(i)} = f_1(\gamma(x^{(i)}),d^{(i)};W^{(i)}(\pi(x^{(i)})))$
n個の中間ベクトル$V^{(i)}$をアベレージプーリング$\psi$で集約し ニューラルネットワーク $f_2()$に入力することで色と密度を取得 $(\sigma,c) = f_2(\psi(V^{(1)},…,V^{(n)}))$
ボリュームレンダリングによってターゲット画像を生成
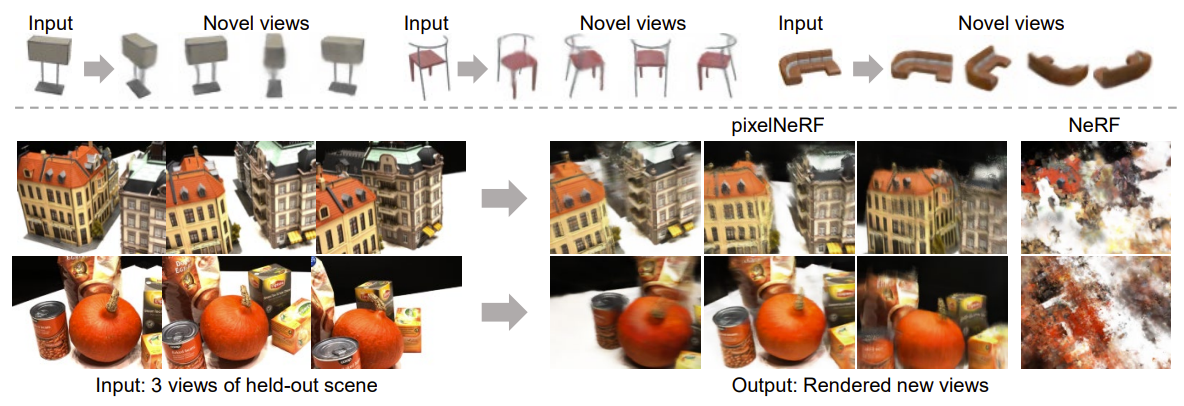
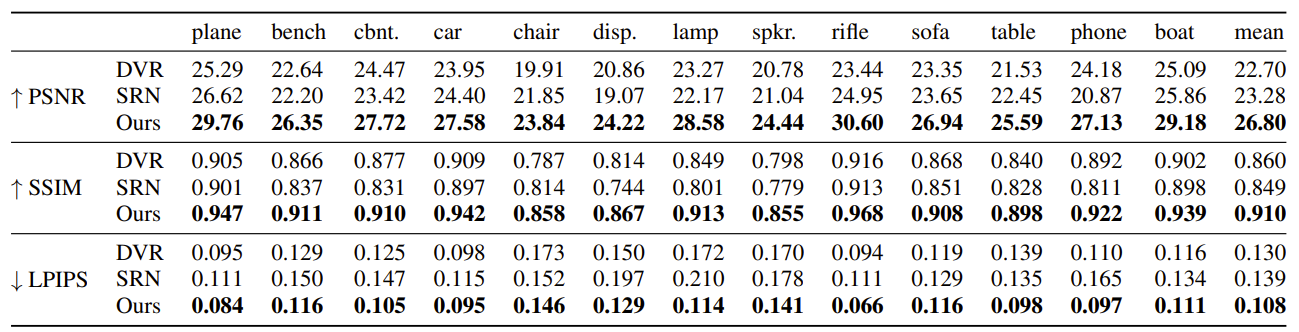
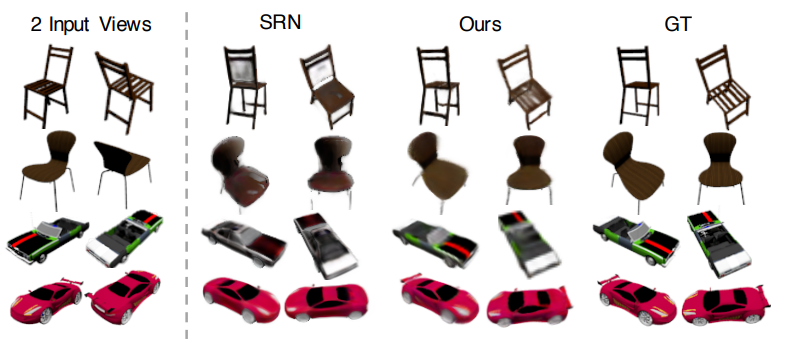
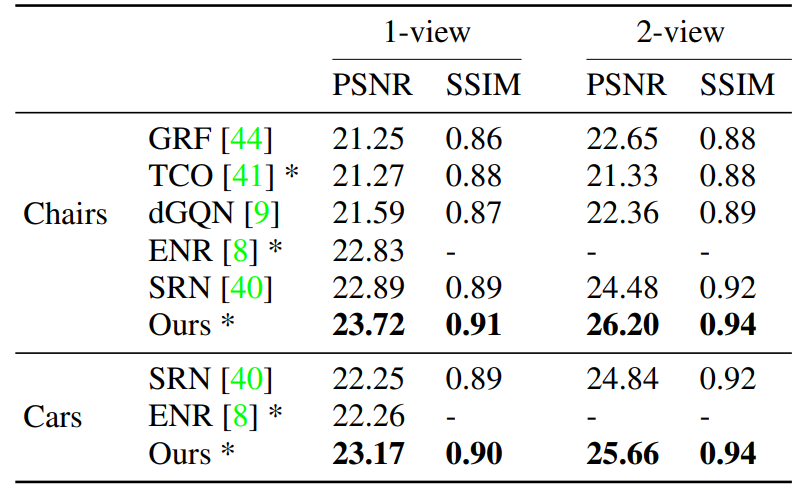
結果
入力画像が1つの場合
入力画像が数枚の場合
一覧へ戻る