軸屋敬介 | Keisuke Jikuya
Home
Note
Blog
Post
End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers
https://arxiv.org/abs/2005.12872
Aug 1, 2022
Object Detection, Transformer,
ECCV (2020)
概要
Transformerと二部マッチングロスに基づく物体検出モデルDETRを提案
すべての物体を一度に予測し、End-to-endで学習される
COCOでチューニングされたFaster R-CNNと同等の性能で、大きい物体に強い
新規性・差分
NMSやアンカーを使用しない
アイデア
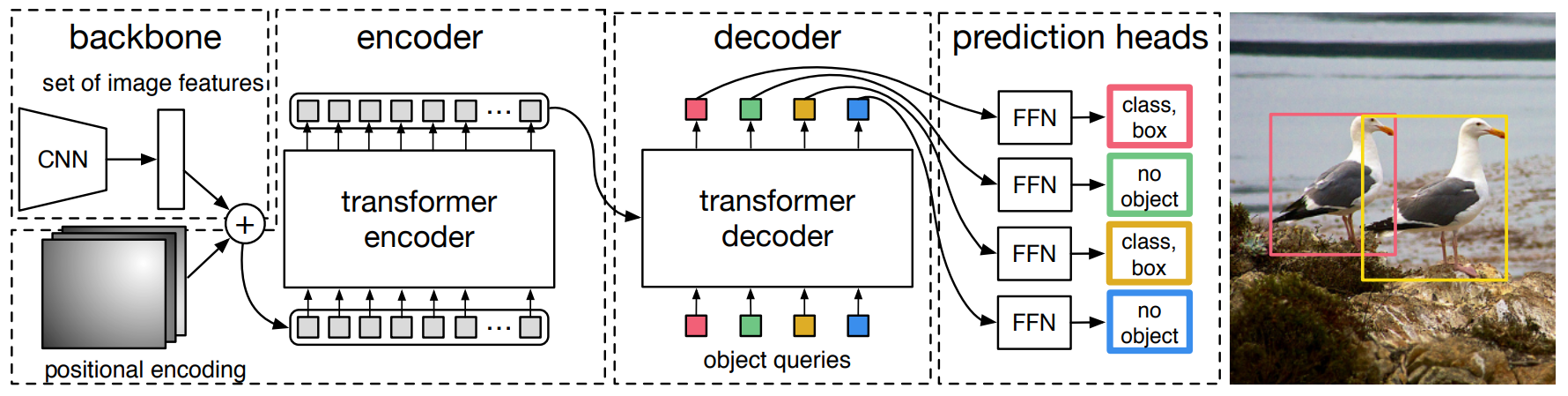
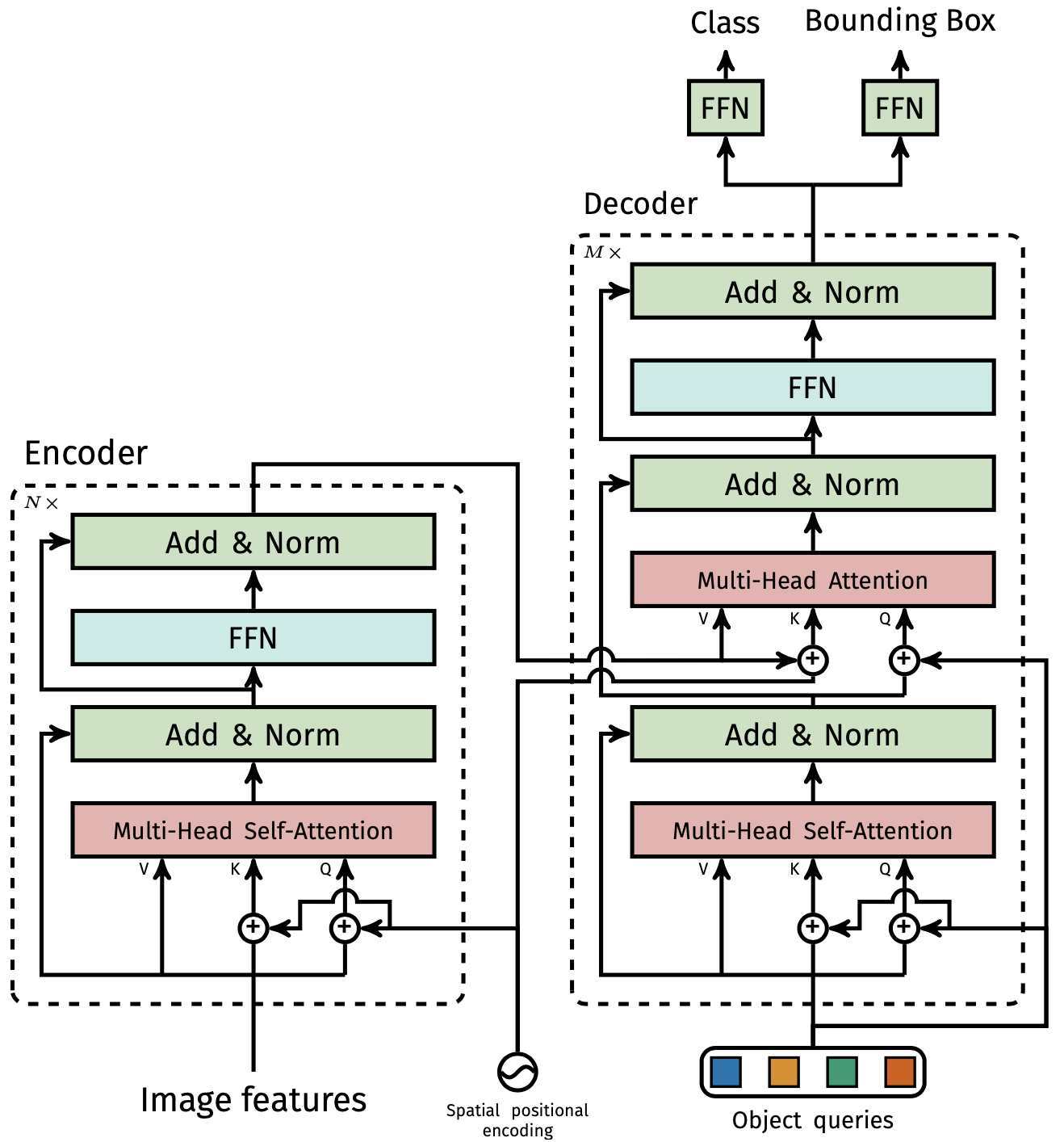
Backbone
画像$x_{img}$をバックボーンCNN(ResNetなど)に通して低解像度の活性化マップ$f$を得る(幅・高さが元の$\frac{1}{32}$、チャンネルが$2048$が一般的)
Transformer
$f$を$1\times1$畳み込みで次元を$d$まで減らす
空間次元を1次元にし($d \times H \times W \rightarrow d\times HW$)、Encoderへ入力
$N$個のObject queriesを入力するDecoderを通じて、$N$個の$d$次元特徴を出力
Prediction feed-forward networks (FFNs)
Decoderの出力を3層パーセプトロンに通してバウンディングボックスの中心座標、高さ・幅を予測
Decoderの出力を別の3層パーセプトロンに通して$N$個のクラスラベルを予測
「オブジェクト数$>N$」の場合、過剰分は背景$\phi$を出力
Loss
予測とGTを1対1で対応させ、ハンガリーLossを計算
\[L_{Hungarian} (y,\hat{y}) = \sum^N_{i=1} [- \log \hat{p}_{\sigma (i)} (C_i) + 1_{c_i\neq \phi} L_{box} (b_i, \hat{b}_{\hat{\sigma}} (i))]\]
バウンディングボックスロス
直接ボックスの予測を行うため、ボックスのサイズによってLossが変わってしまう
そこで、$L_{iou}$の線形結合を行いスケール不変にする
\[L_{box} = \lambda_{iou} L_{iou} (b_i, \hat{b}_{\sigma (i)}) + \lambda_{L1} \| b_i - \hat{b}_{\sigma (i)} \|_1\]
\[L_{iou} = 1 - (\frac{b_{\sigma(i) } \cap \hat{b}_i}{b_{\sigma(i)} \cup \hat{b}_i} - \frac{B (b_{\sigma(i) }, \hat{b}_i) \backslash b_{\sigma(i) } \cup \hat{b}_i}{B(b_{\sigma(i) }, \hat{b}_i)})\]
結果
COCO Validationの結果
小さい物体はFaster RCNNが強く、それ以外はDETRが勝っている
一覧へ戻る