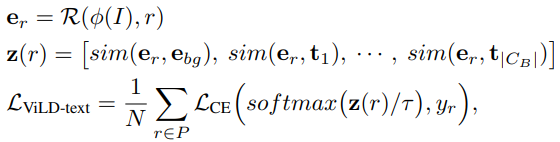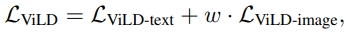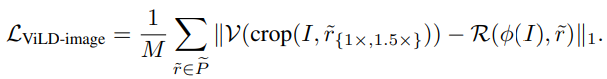Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/vild
Mar 31, 2023
Object Detection, Zero-shot Learning, Vision and Language,
ICLR (2022)
概要
- 任意のテキストで物体検出をするオープンボキャブラリ物体検出器ViLD(Vision and Language knowledge Distillation)を提案
- オープンボキャブラリの画像分類である教師モデルから2段階の検出器である生徒モデルに知識蒸留する
- ResNetやALIGNをバックボーンとして、PASCAL VOC、COCO、Objects365で高精度が出た
新規性・差分
アイデア
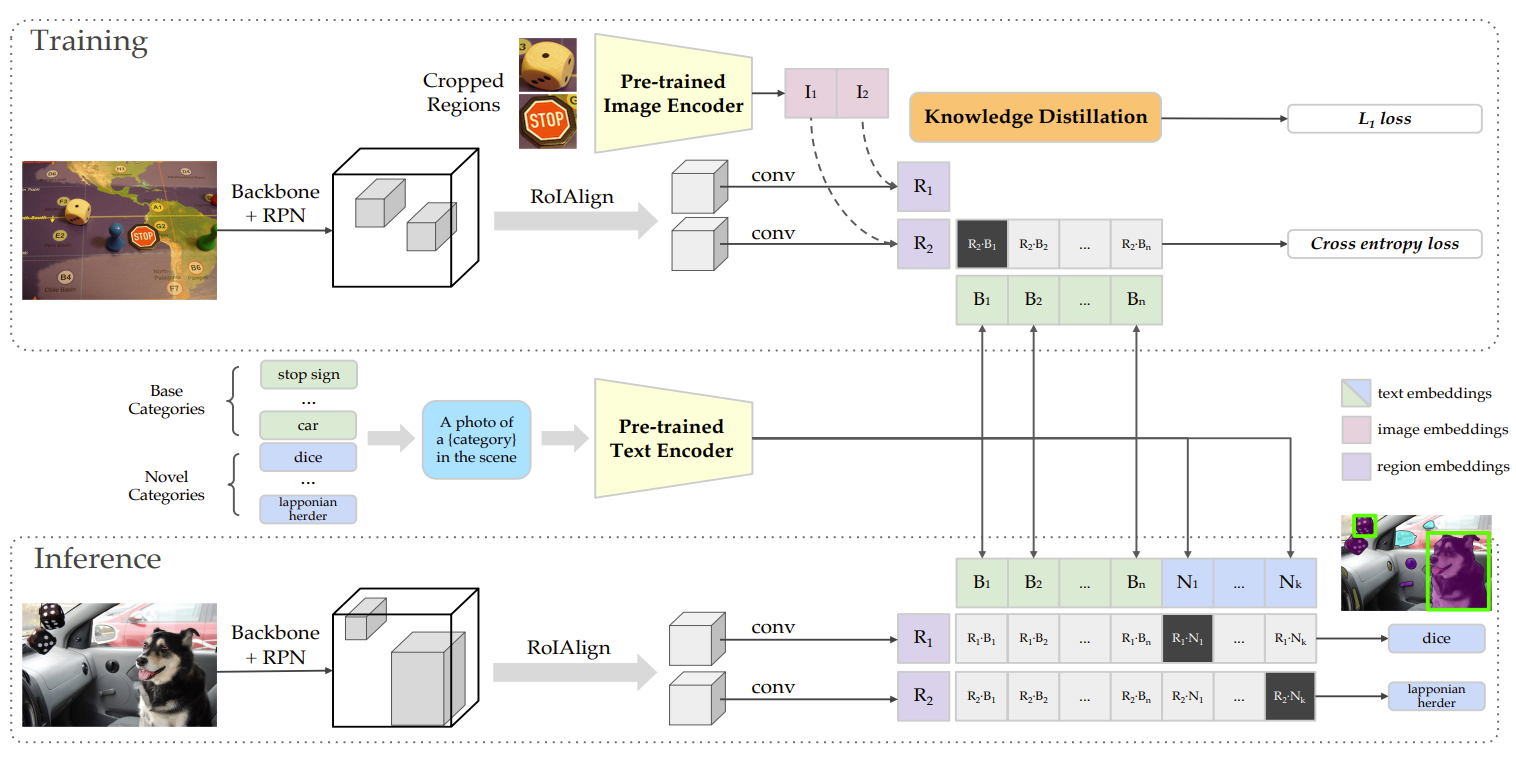
- 変数
- 教師データセットを基本サブセット$C_B$と新規サブセット$C_N$に分ける
- テキストEncoder $T()$, 画像Encoder $V()$
- 位置の検出
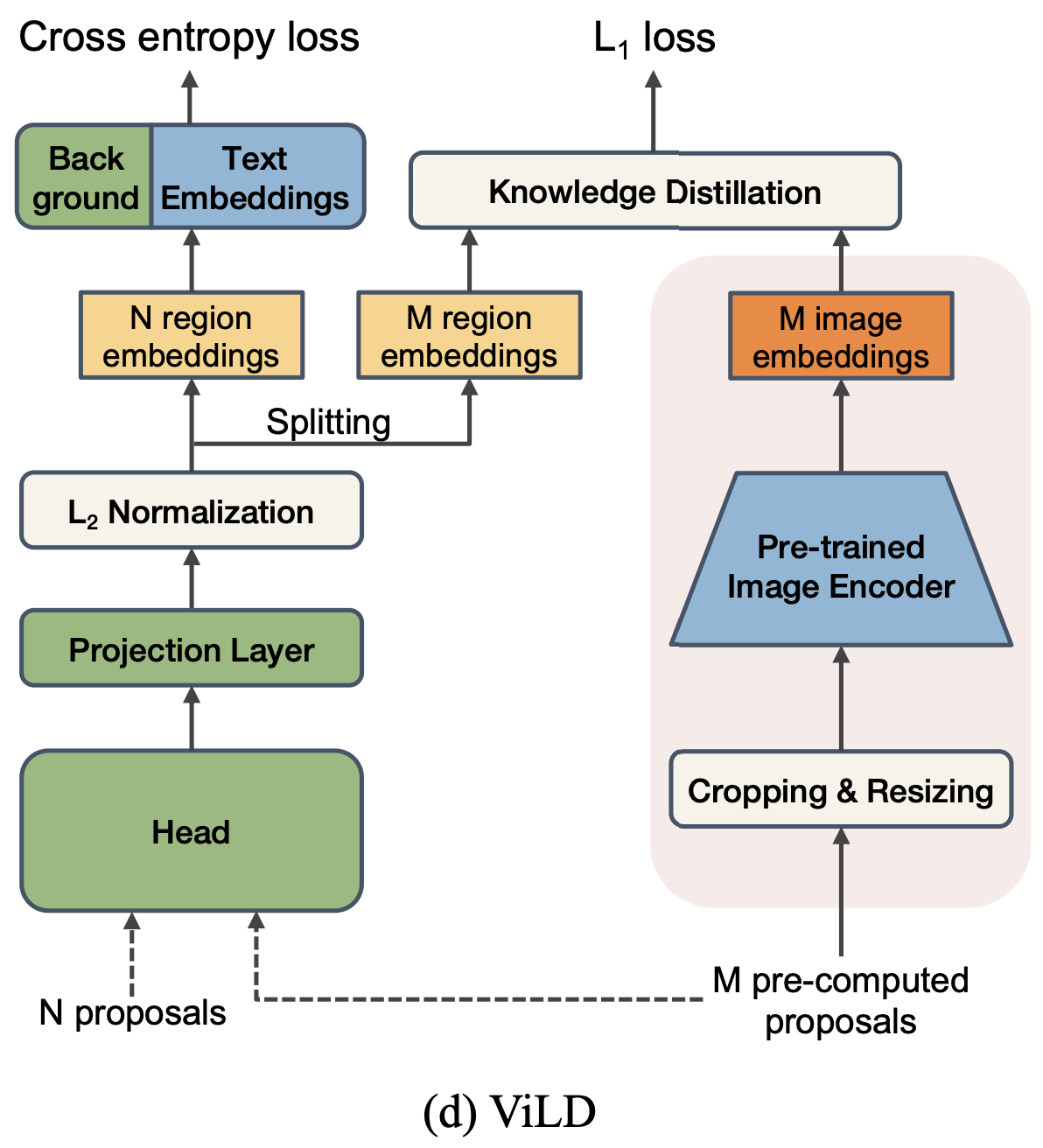
- Mask R-CNNのような二段階物体検出器をベースとする
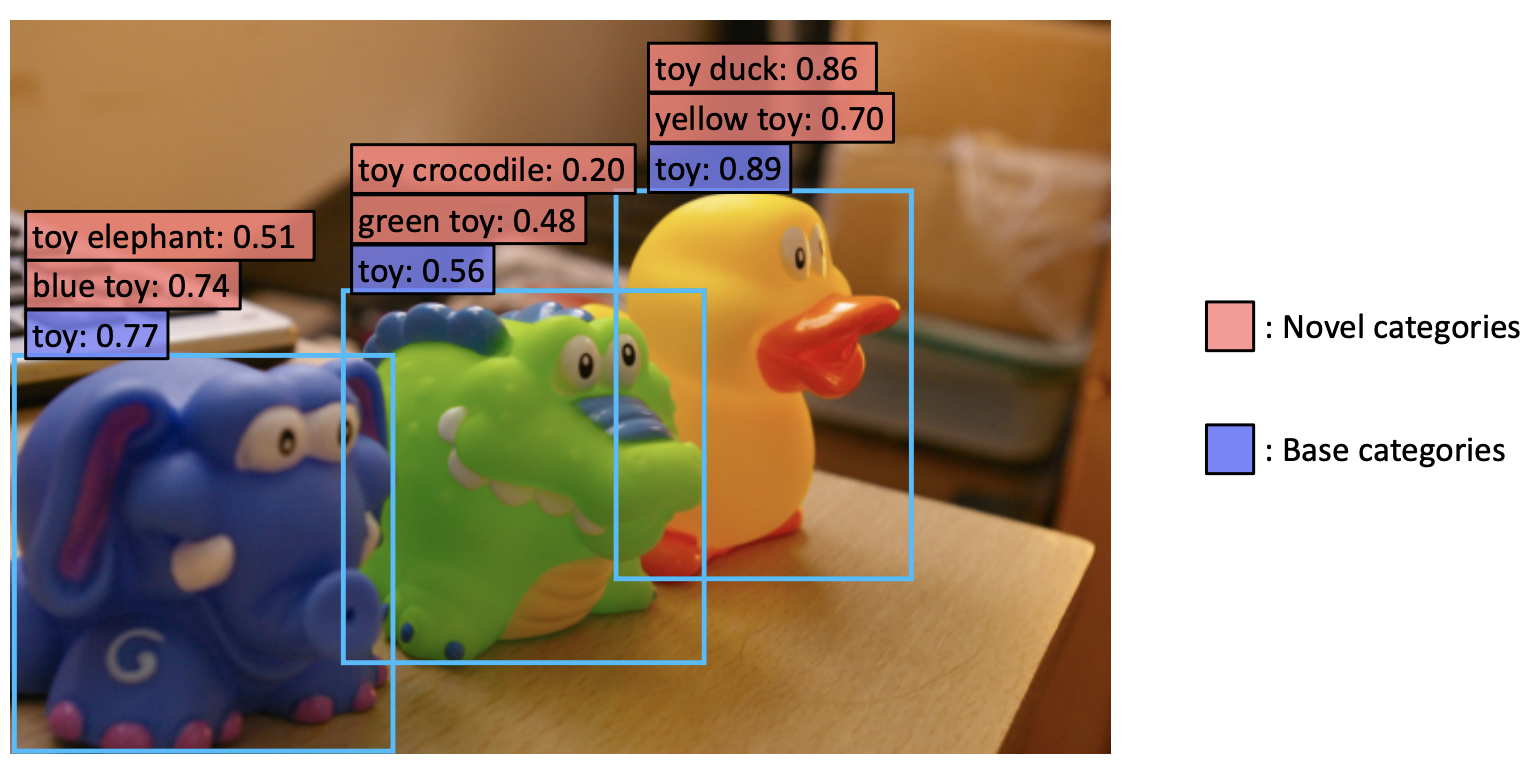
- Open Vocab検出
- 検出した位置を切り抜き
- 画像埋め込み
- 基本サブセット$C_B$を用いて位置提案ネットワークを学習し、提案領域を得る
- 提案領域の切り抜きとリサイズをして,事前学習済み画像Encoder$V()$で画像埋め込みを得る
- テキスト埋め込み
- カテゴリー名をプロンプトテンプレート(例:「a photo of {category} in the scene」)にして,テキストEncoder $T()$でテキスト埋め込みを得る
- 画像とテキストの埋め込み間のコサイン類似度を計算
- すべての提案領域に対し,画像Encoder$V()$に通すので推論は低速
- Vision&Languageの知識蒸留
- 推論の遅さを解決するため
- ViLD-text
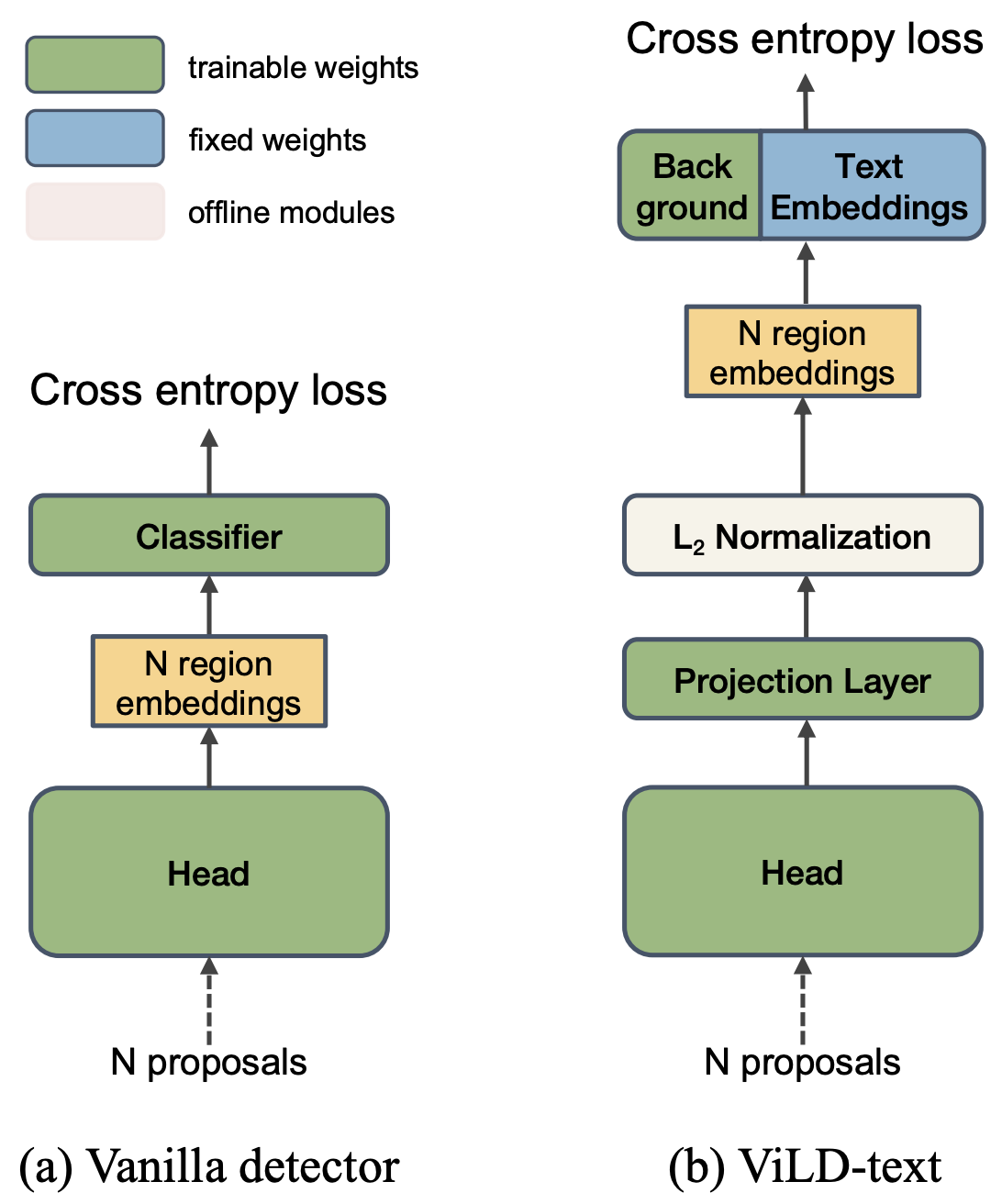
- 検出器の分類を前述のテキスト埋め込みに置き換え
- 背景というテキストは表現できないので独自の埋め込みを学習
- すべてのカテゴリとのCos類似度を出しクロスエントロピーを計算
- 推論時には新規カテゴリに対して,テキスト埋め込みを追加することで新規カテゴリに対応
- ViLD-image
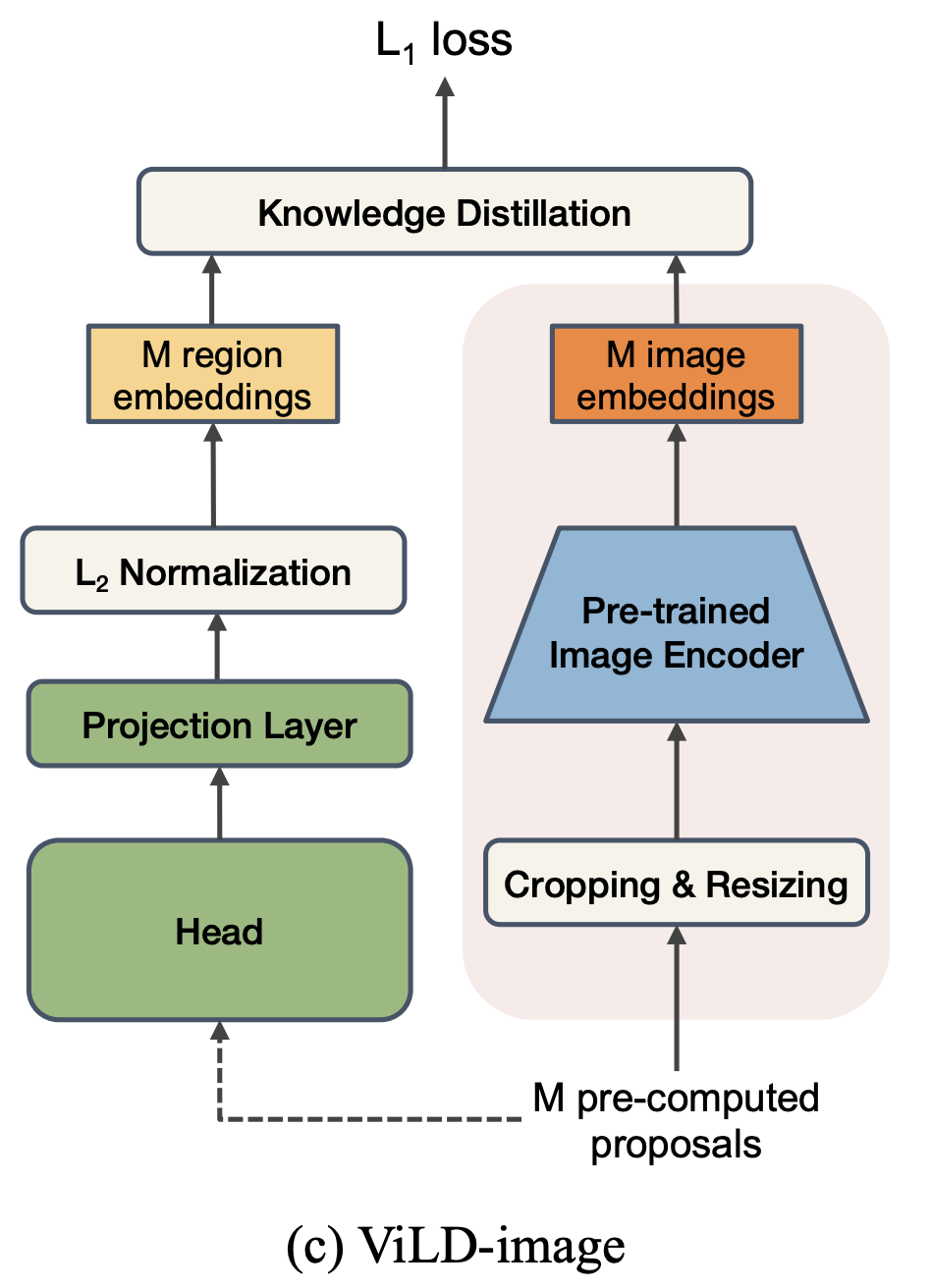
- Mask R-CNNで切り取った特徴が、前述の画像埋め込みと一致するように学習することで知識蒸留(L1距離の最小化)
- 組み合わせた最終形態
結果
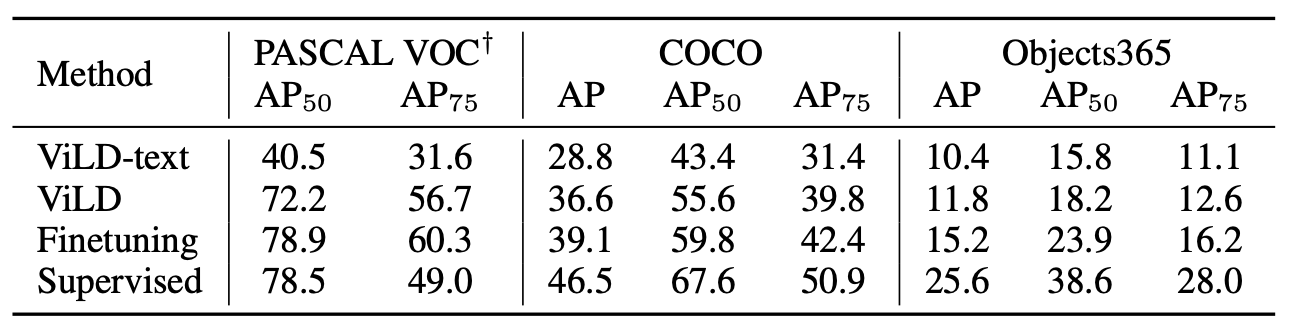

- PASCAL VOCで72.2 AP
- COCOで36.6 AP
- Objects365で11.8 AP