OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
https://github.com/OFA-Sys/OFA
Nov 29, 2022
Multimodal Pretraining, Multitask Learning, Unified Frameworks, Zero-shot Learning, Transformer,
ICML (2022)
概要
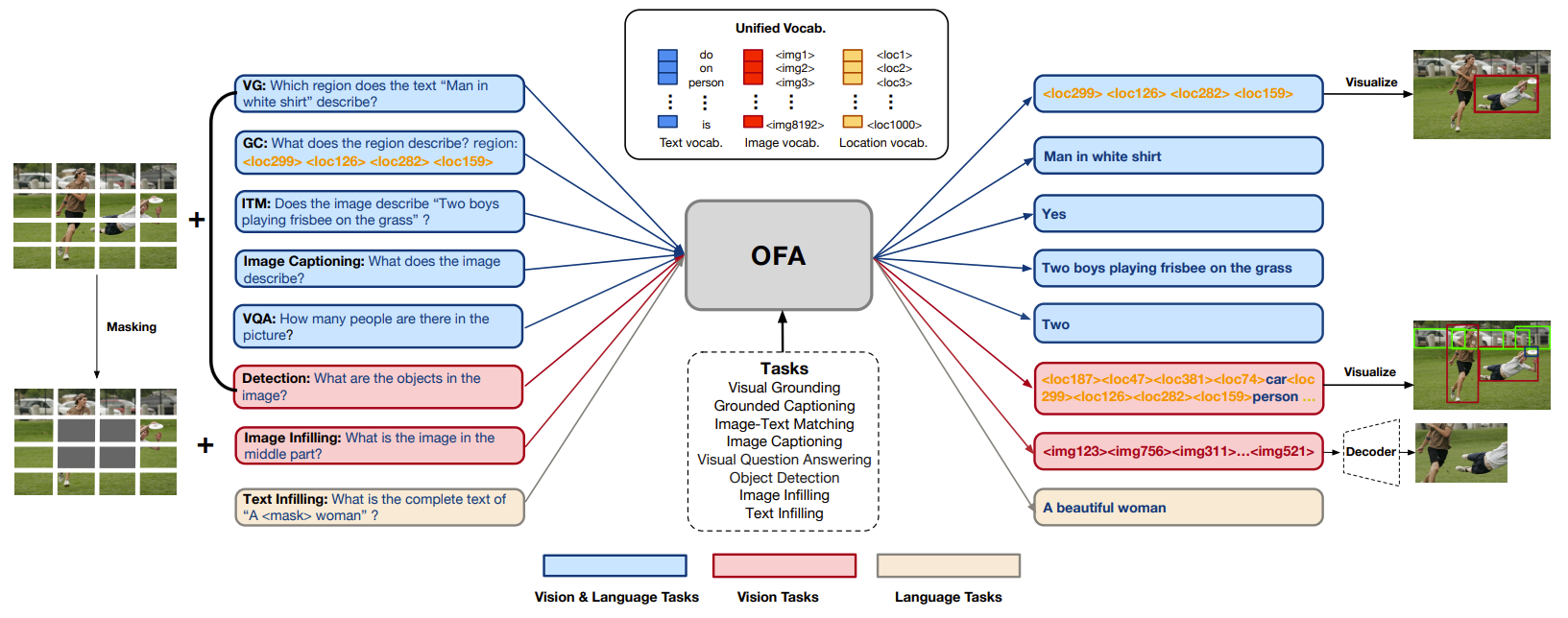
- 包括的なタスクを行うことができる、タスクとモダリティを無視できるフレームワークであるOFA(One For All)を提案
- Text2Image, Visual Grounding, VQA, Image Caption, Image Classification, language modeling
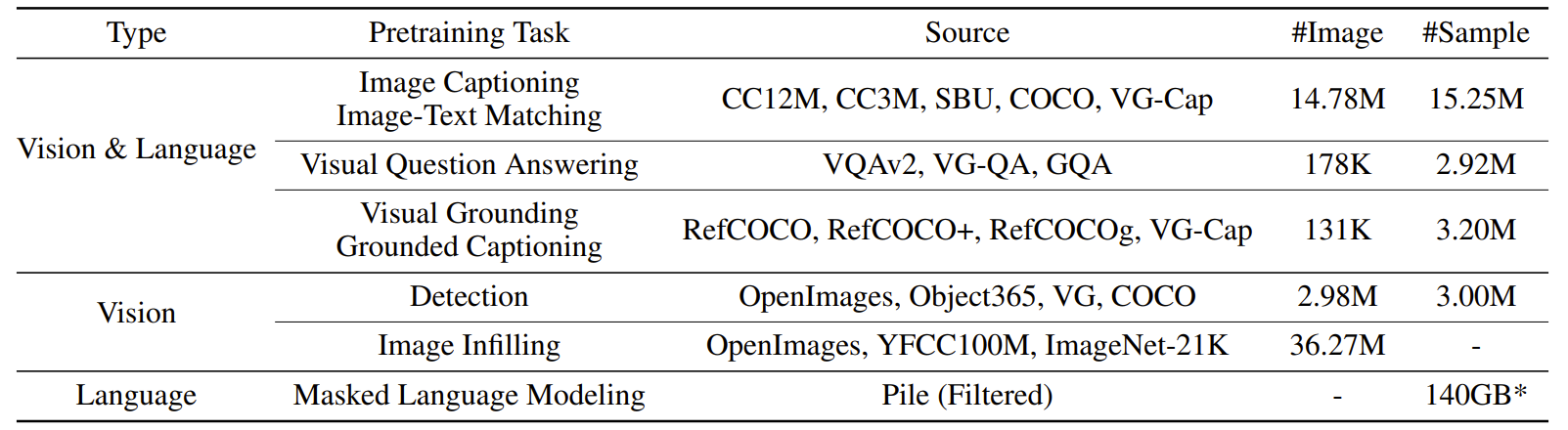
- 一般に公開されている2000万件の画像テキストペアのデータセットで事前学習
- 自然言語理解(RoBERTa、ELECTRA、DeBERTa)
自然言語生成(UniLM、Pegasus、 ProphetNet)
画像分類(MoCo-v3、BEiT、MAE)と同等のパフォーマンスを達成
- 未学習のタスクにも移行できる
新規性・差分
- 下流タスクであるVQAや画像キャプションでの性能劣化が起きない
- 画像生成機能を持っている
アイデア
- アーキテクチャ
- TransformerベースのEncoder Decoderフレームワーク
- テキストと画像に対して絶対位置埋め込み
- ハイパラ
- 事前学習
結果
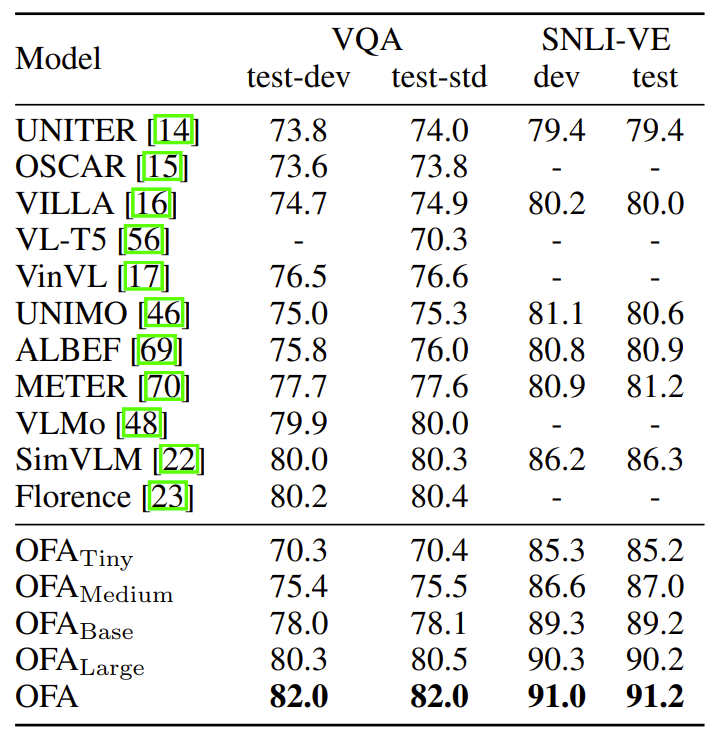
- VQA and visual entailment
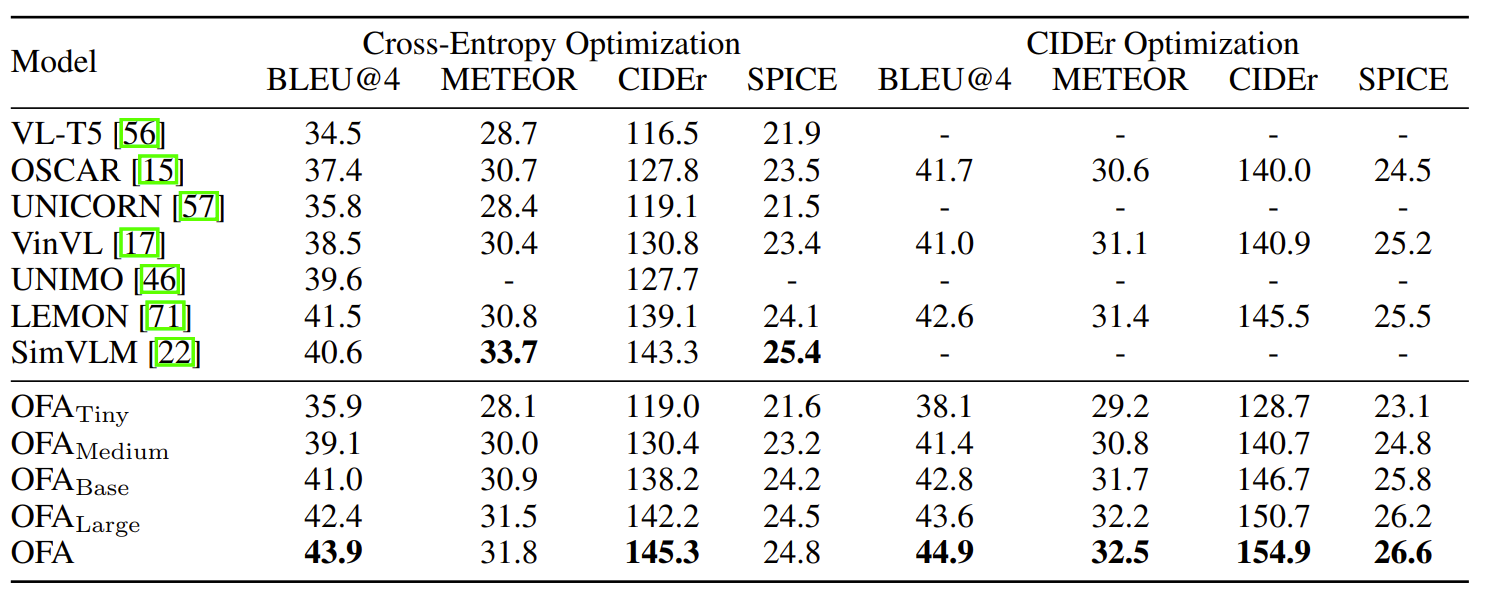
- MSCOCO Image Captioning
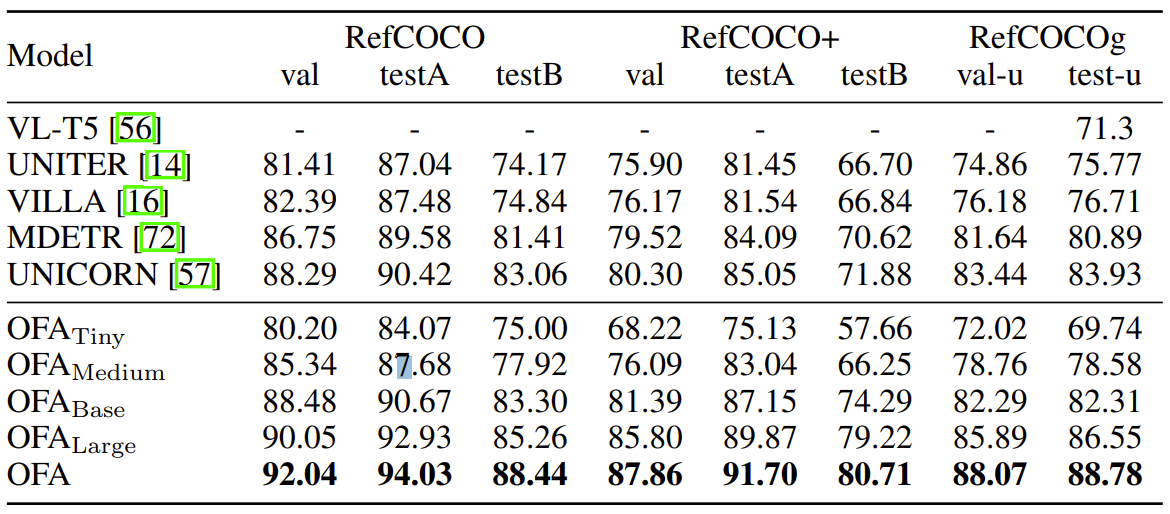
- RefCOCO, RefCOCO+, RefCOCOg
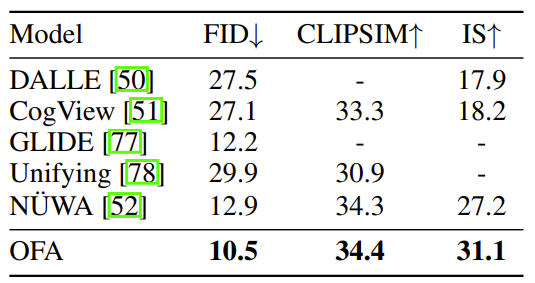
- text-to-image generation task
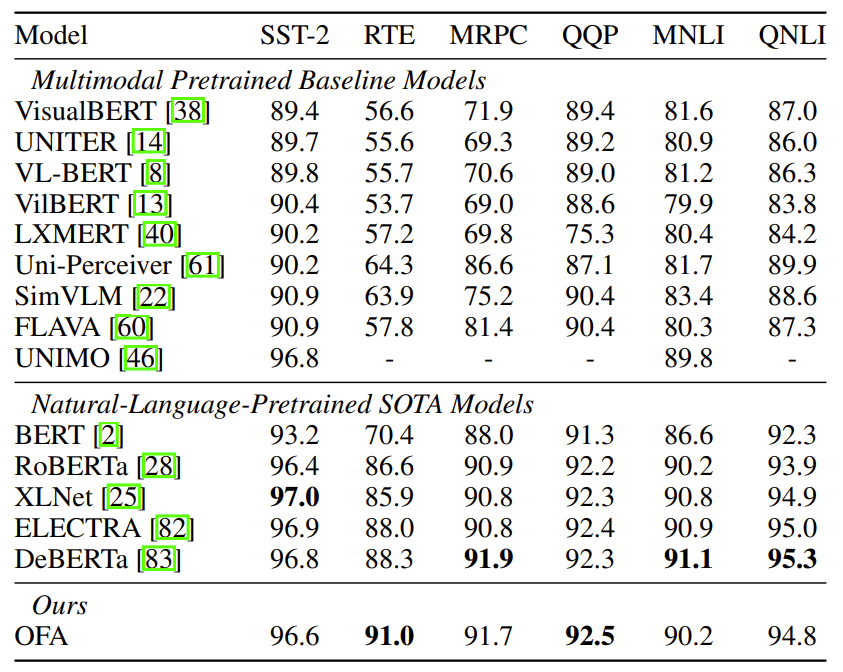
- GLUE benchmark datasets
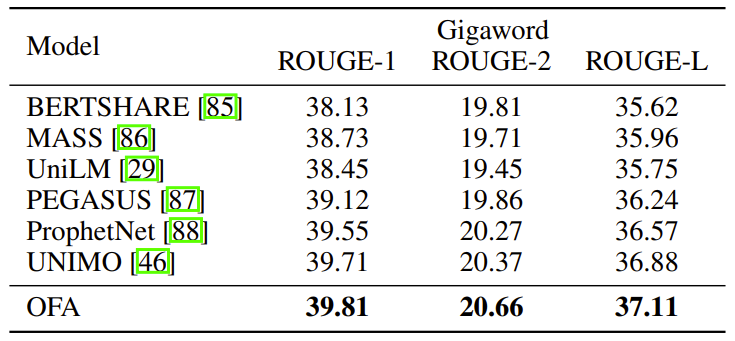
- Gigaword abstractive summarization
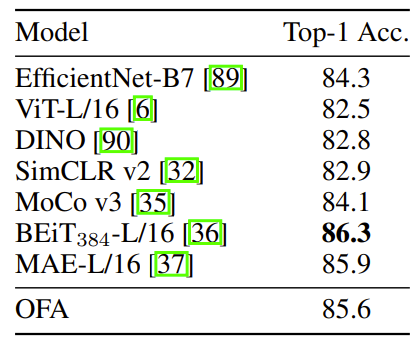
- ImageNet-1K
- unseen task grounded QA
- unseen domain VQA