Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo: a Visual Language Model for Few-Shot Learning
https://www.deepmind.com/blog/tackling-multiple-tasks-with-a-single-visual-language-model
Mar 14, 2023
Vision and Language, Few-shot Learning, Transformer,
NeurIPS (2022)
概要
- 少数のアノテーションで重みの更新なしに新しいタスクに迅速に対応できるVision&LanguageモデルであるFlamingoを提案
- 数千倍のタスク専用データでFinetuningに対して、6/16のタスクでSotA


新規性・差分
- 言語モデルのFew-shot学習をPerceiver-basedアーキテクチャなどを用いて画像やビデオを入力できるように拡張
アイデア
- 概要
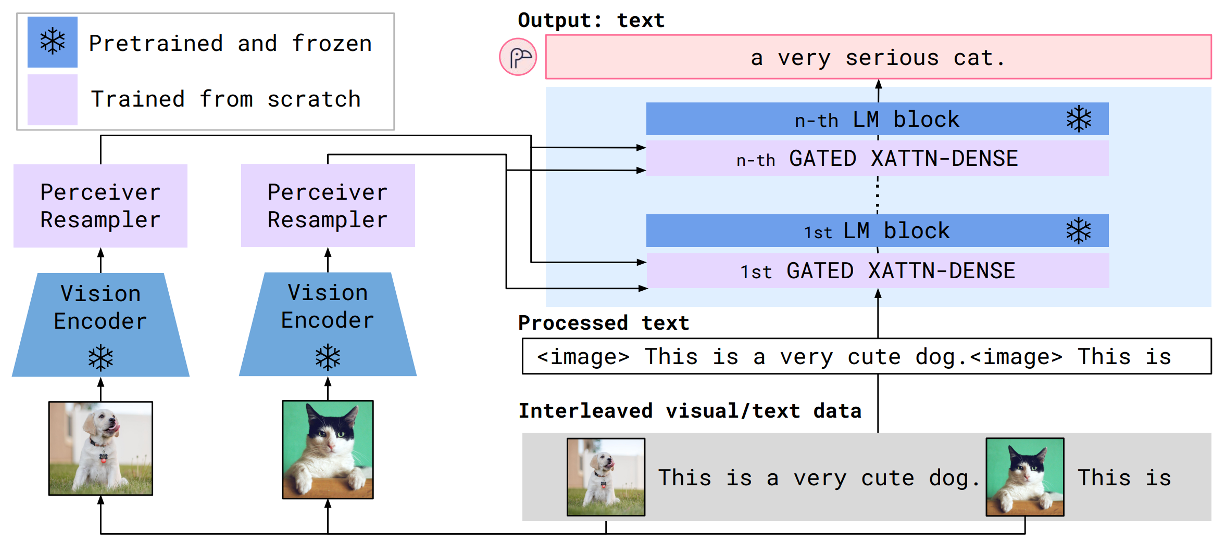
- Vision Encoderから画像または動画の特徴を取得し、Perceiver Resamplerで固定数の画像トークンにする
- 画像トークンをCross AttentionでLM layerの間に挟むことで、LM Blockを視覚情報で条件付けする
- Vision Encoder
- 事前学習済みNormalizerFree ResNet (NFNet)を使用
- ビデオの場合は1FPSごとにEncoderに通し、時間埋め込みを追加
- Perceiver Resampler
- サイズの異なる特徴マップを固定数の画像トークンを生成
- V&L Sampler Moduleによって通常のTransformerやMLPを凌駕
- GATED XATTN-DENSE layers within a frozen pretrained LM
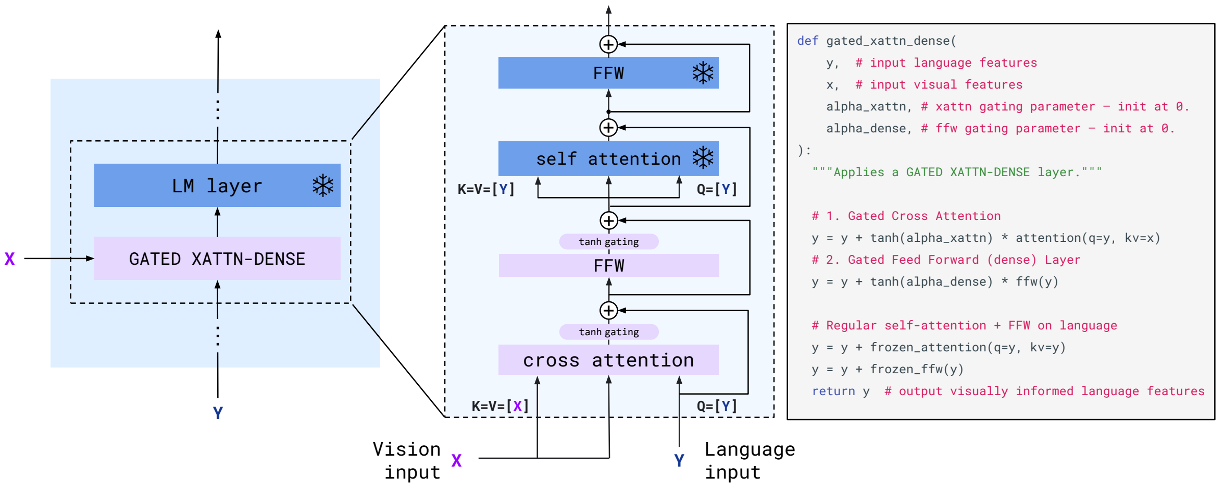
- 事前学習済みのLM layer(Chinchilla)を用意し、重みは固定する
- その中にGATED XATTN-DENSE layersを挿入
- 残差ブロックの接続前にtanhを掛けることで、学習の安定化と性能の向上
- Vision&Languageデータセットで学習
- M3W(画像とテキストが交互に並ぶデータセット)
- ALIGN, LTIP(画像とテキストのペア)
- VTP(動画とテキストのペア)
結果
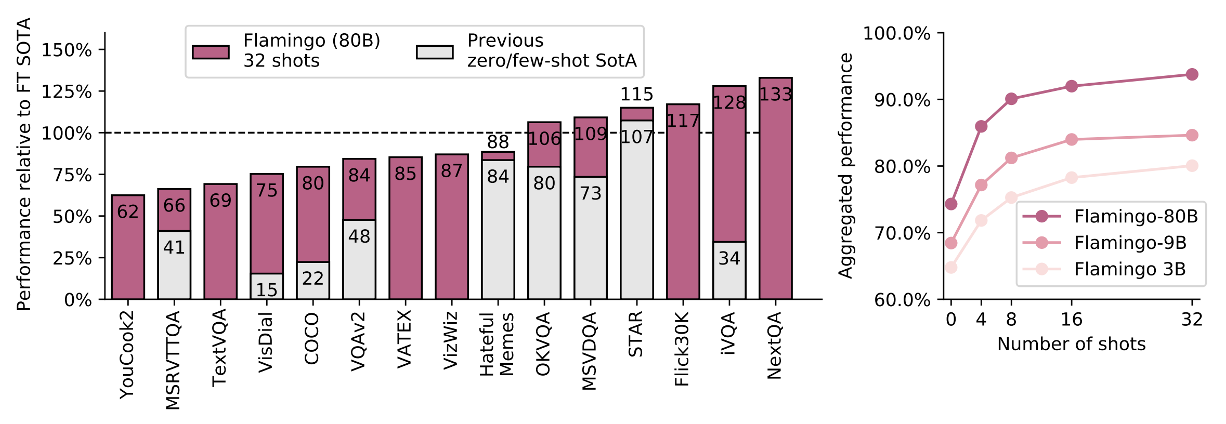
- Few-shot learning
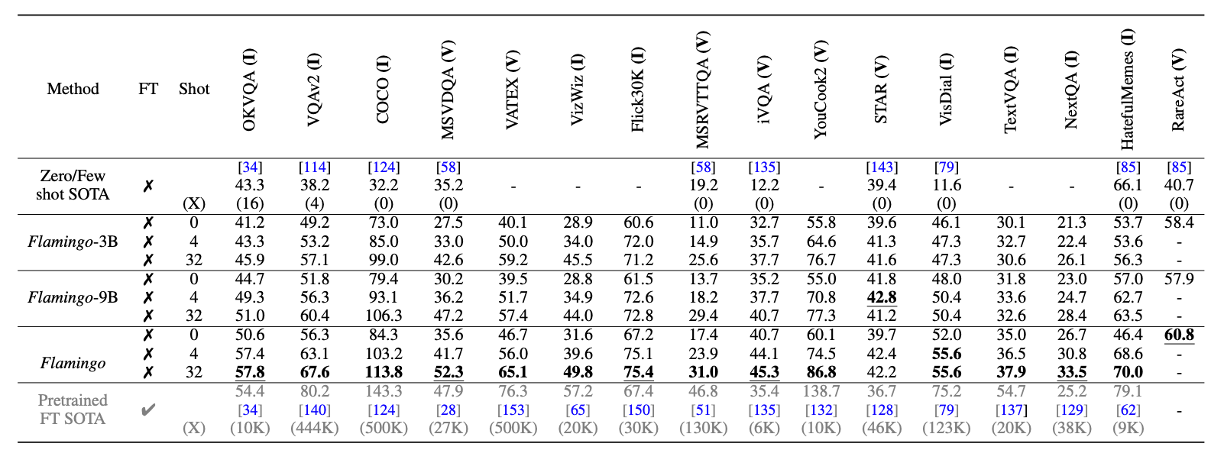
- FlamingoはFinetuningを行わずに16個中6個のタスクでSotA
- 比較対象(100%)はFinetuning(重みの更新)済みの最新手法
- また、白色のZero/Few Shotを上回る
- Finetuning

- FewshotでSotAを上回らなかった9個中5個のタスクでSotA
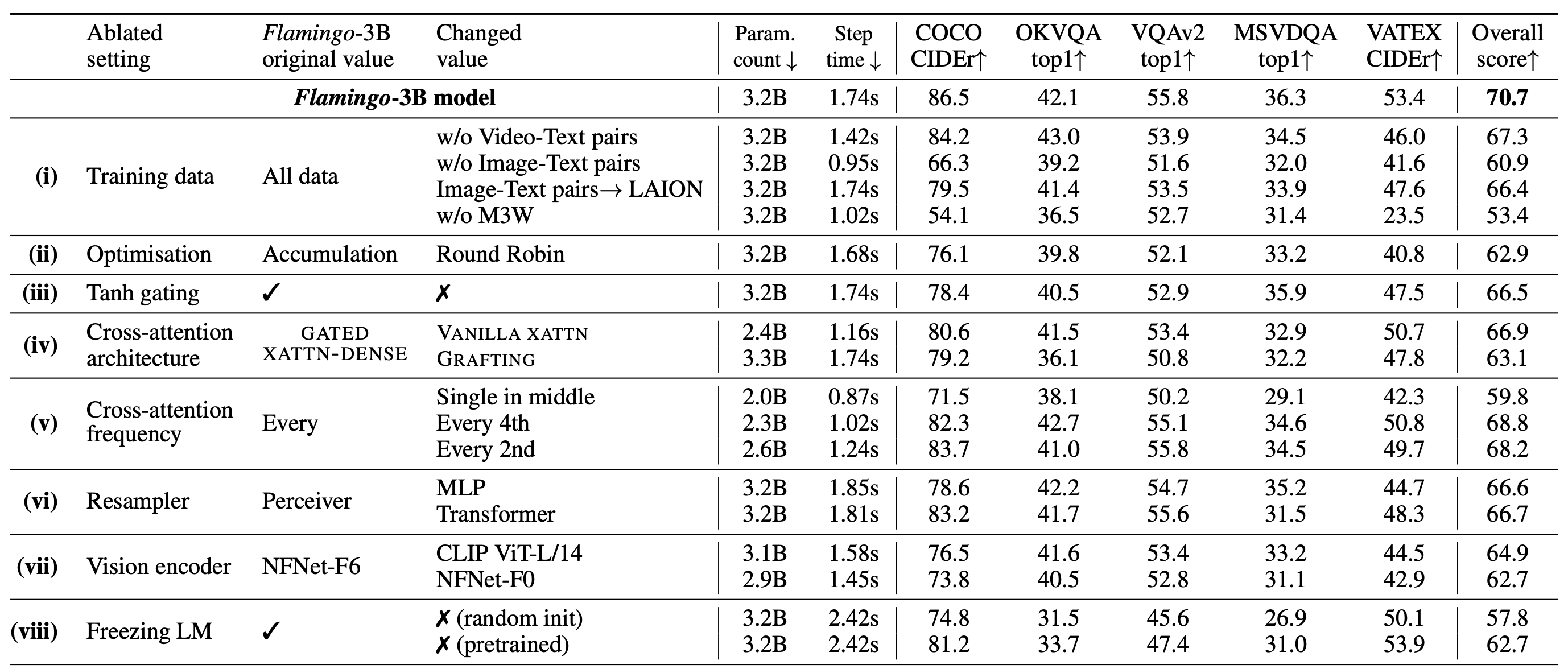
- Ablation studies