軸屋敬介 | Keisuke Jikuya
Home
Note
Blog
Post
Visual Programming: Compositional visual reasoning without training
Visual Programming: Compositional visual reasoning without training
https://prior.allenai.org/projects/visprog
May 1, 2023
Transformer, Vision and Language,
CVPR (2023)
概要
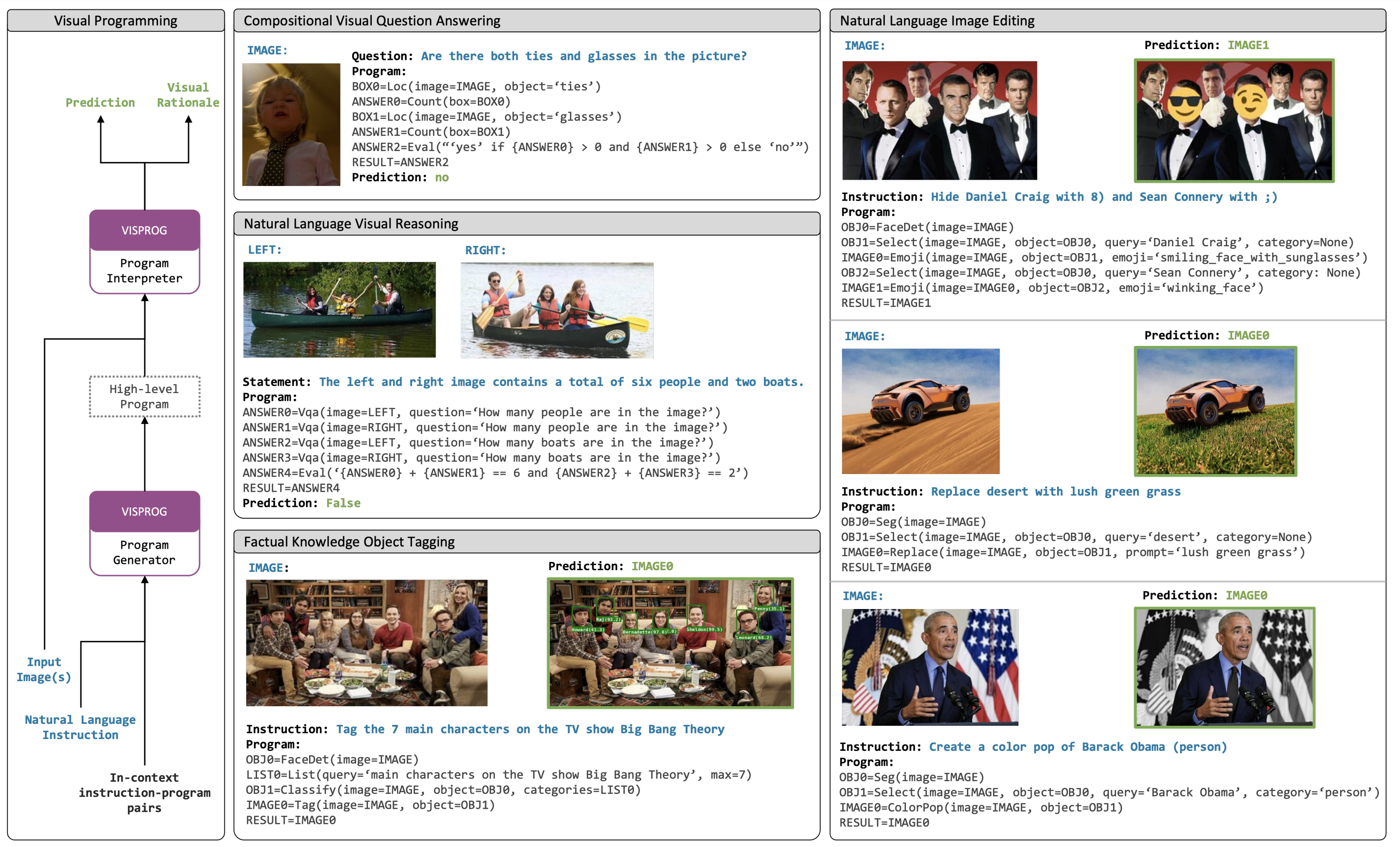
1枚または複数枚の画像と自然言語の命令を与え、GPT-3を利用して命令プログラムを作成し、そのプログラムを実行することで目的の出力を得るシステムVISPROGを提案
命令プログラムの各行では、CVモデル・言語モデル・OpenCVの画像処理・演算子のいずれかのモジュールを実行し、後続で使用できる中間出力を生成している
事実知識オブジェクトタグ付け・言語ガイド付き画像編集などの4つのタスクで柔軟性を実証
新規性・差分
Neural Module Networksに比べて、GPT-3によって訓練を必要とせずに少数の例からプログラムを作成できる
中間出力を確認することで、間違いの理由や視覚的根拠を得ることができる
アイデア
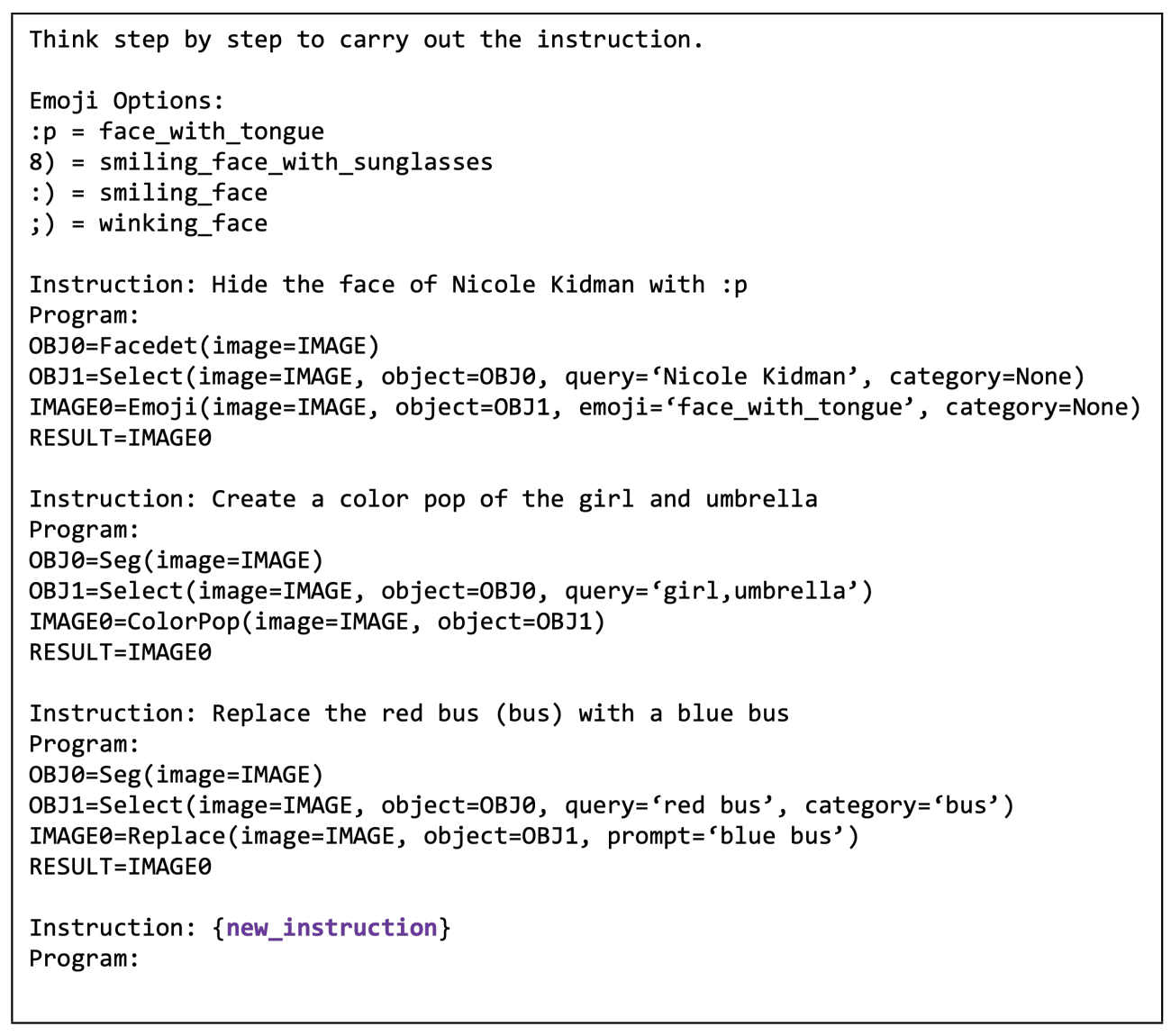
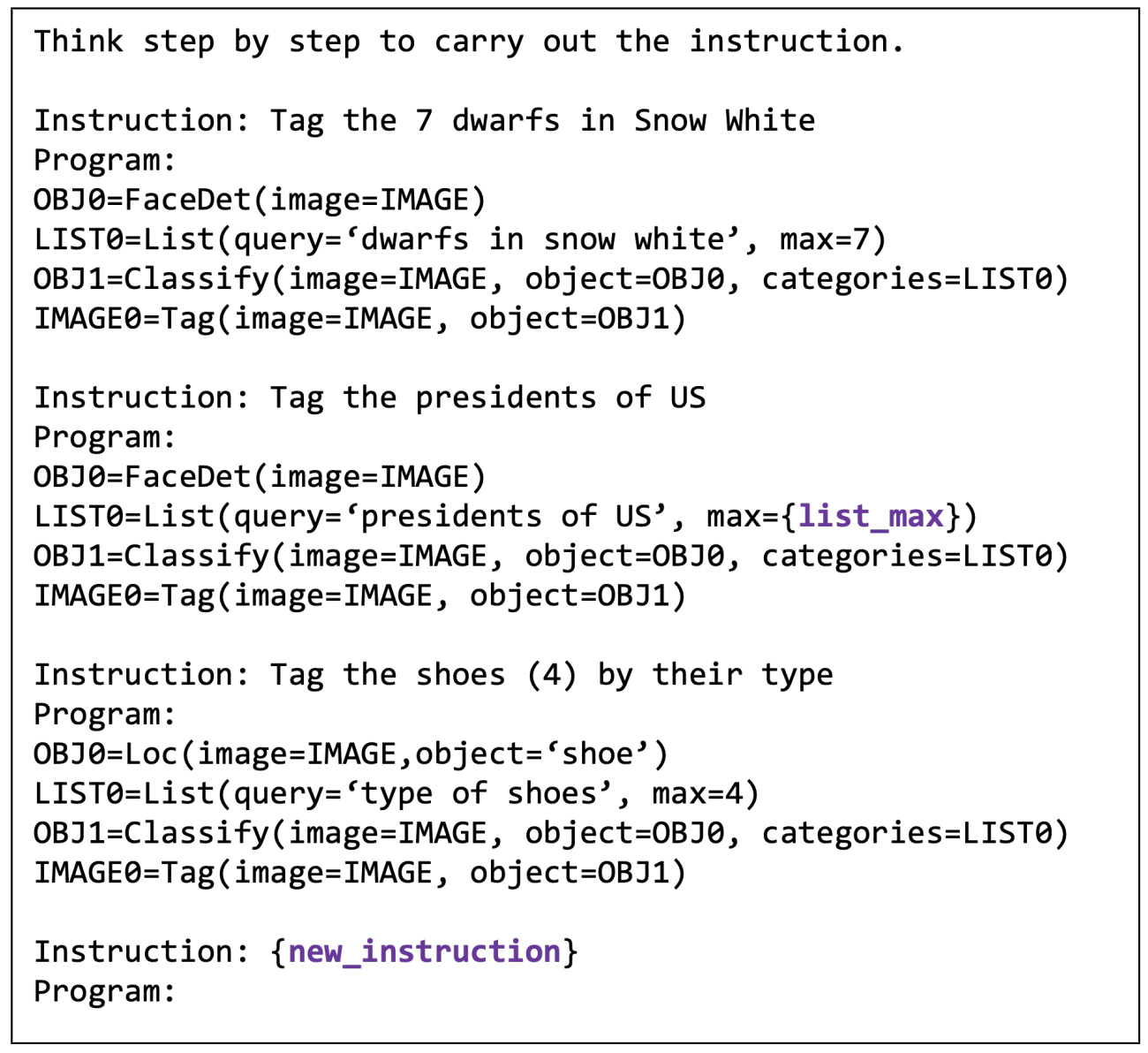
GPT-3は入力と出力のデモを与えることで、入力から欲しい出力を得ることができる
これを利用し、命令とプログラムのデモを与えることで、目的のプログラムを得る(画像編集タスクの例)
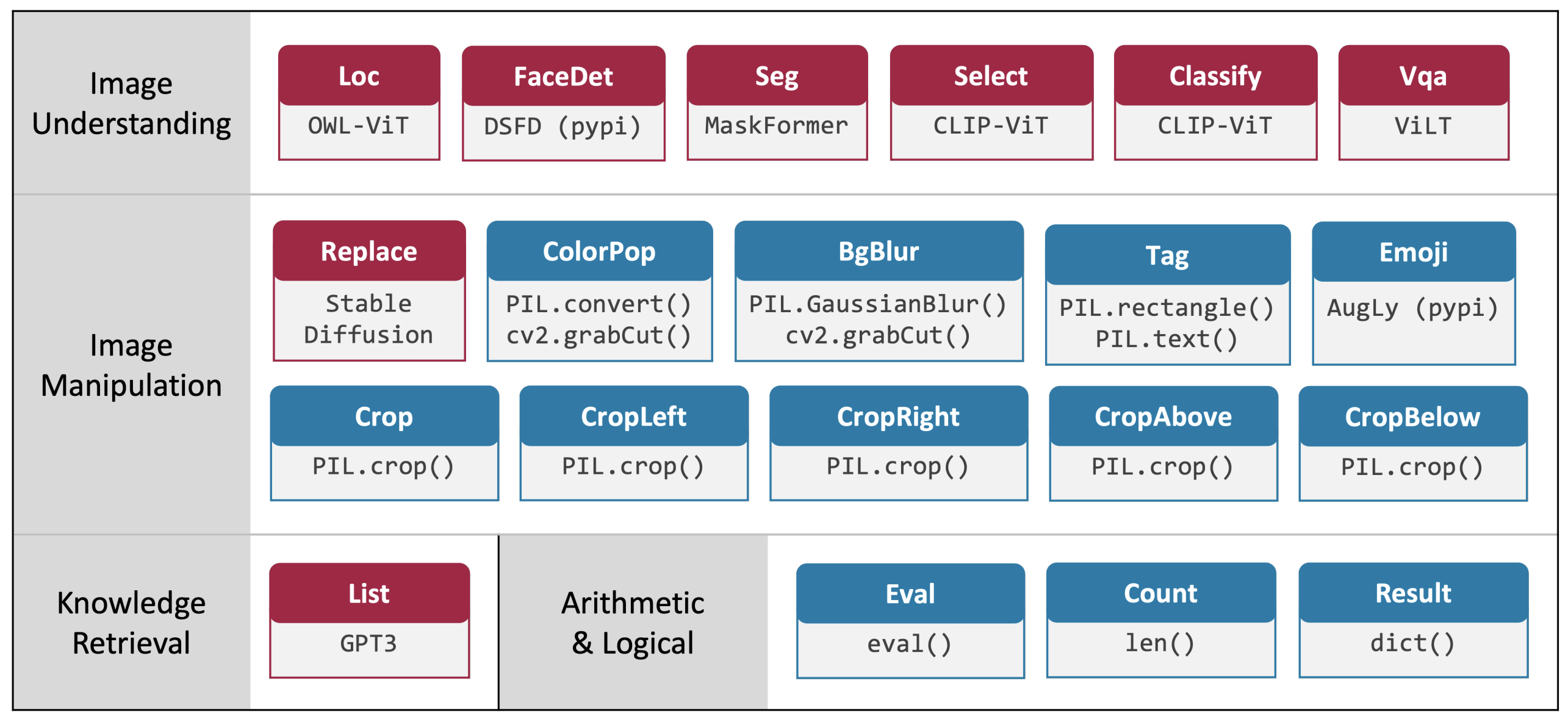
GPT-3が各モジュールの入出力や機能を理解できるように、説明的なモジュール名(Select, Replaceなど)、引数名(image, objectなど)、変数名(IMAGE, OBJ)を用いている
各モジュールはPythonのクラスとして実装されている
行を解析して入力引数名と値、出力変数名を抽出
学習済みNNを含む計算を実行し、出力変数名と値でプログラムの状態を更新
htmlを用いて計算を視覚的に要約
現在サポートされているモジュール(赤はNNモデル, 青は画像処理などのPythonルーチン)
視覚的要約
例(画像編集タスク)
例(NLVRタスク)
この視覚的要約によって、プログラムの論理的な正しさや失敗の原因が理解できる
タスクとプロンプト
合成VQAタスク
例:「ヘルメットをかぶっている人の左側に小さなトラックがあるか、右側にあるのか?」
NLVR
画像ペアに対するVQA
知識タグ付けタスク
画像に写っている人物や物体の名前を識別
画像編集タスク
結果
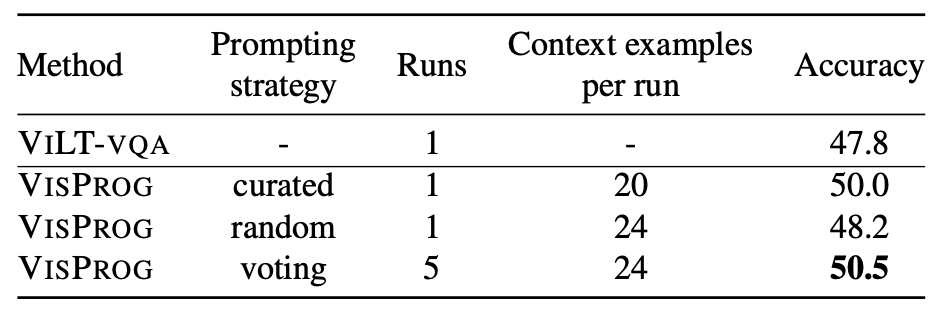
合成VQAタスク
2.7ポイントUP
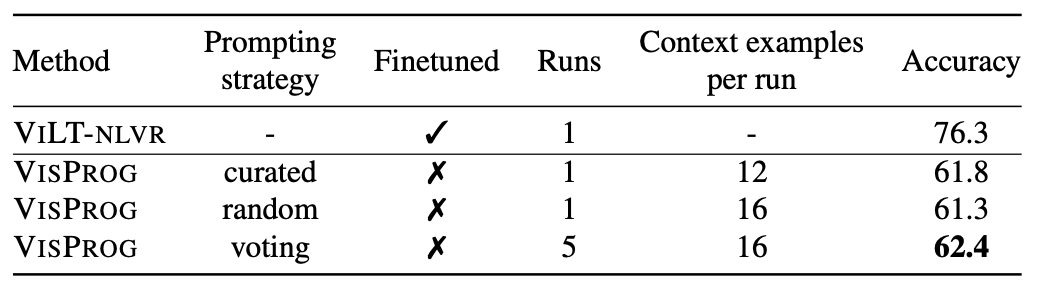
NLVR
62.4%の高いゼロショット精度
知識タグ付けタスク
画像編集タスク
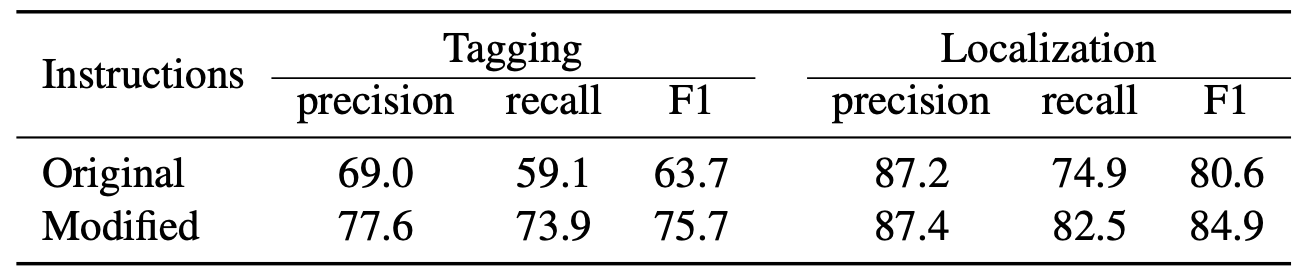
視覚的要約による失敗原因の解明とプロンプトの修正
関連論文
PROGPROMPT: Generating Situated Robot Task Plans using Large Language Models
一覧へ戻る