Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks
Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks
https://unified-io.allenai.org/
May 8, 2023
Multimodal Pretraining, Multitask Learning, Unified Frameworks, Zero-shot Learning, Vision and Language,
ICLR (2023)
概要
- 統一された入力と出力を使用して、姿勢推定、物体検出、深度推定、画像生成などのCVタスク、領域キャプションや参照表現などのVLタスク、質問応答やテキスト要約などのNLタスクを実行する統合モデルUNIFIED-IOを提案
- UNIFIED-IOは、単一のtransformerベースのアーキテクチャを使用して、CVとNLの90を超える多様なデータセットを共同でトレーニングできる
- GRITベンチマークで7つのタスクすべてを実行できる最初のモデルであり、NYUv2-Depth、ImageNet、VQA2.0、OK-VQA、Swig、VizWizGround、BoolQ、およびSciTailなどの16の多様なベンチマークでタスク固有のFinetuningなしで優れた結果
新規性・差分
- モダリティ固有のブランチを必要とせずに、GRITベンチマークで7つのタスクをサポートする最初のモデル
アイデア
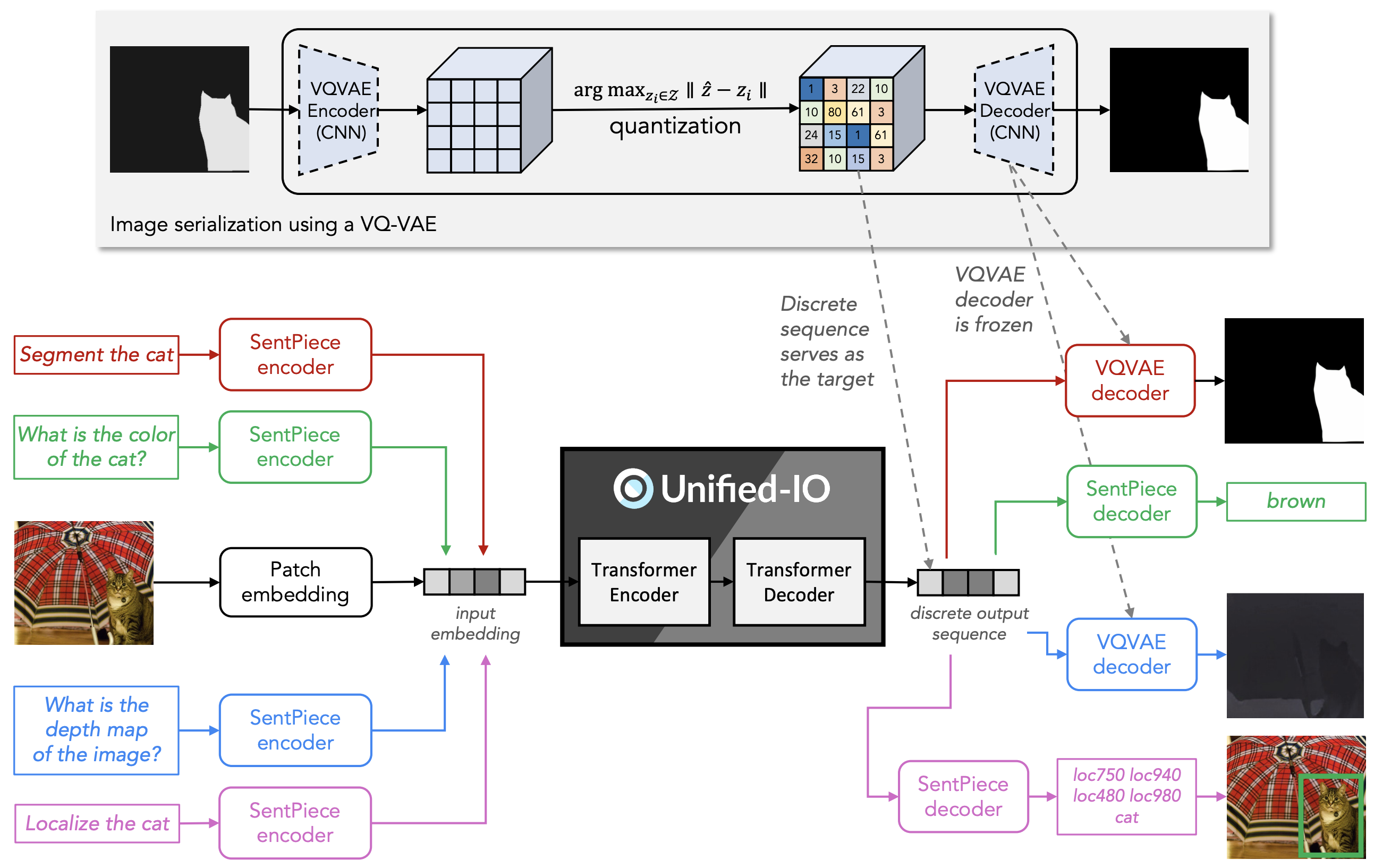
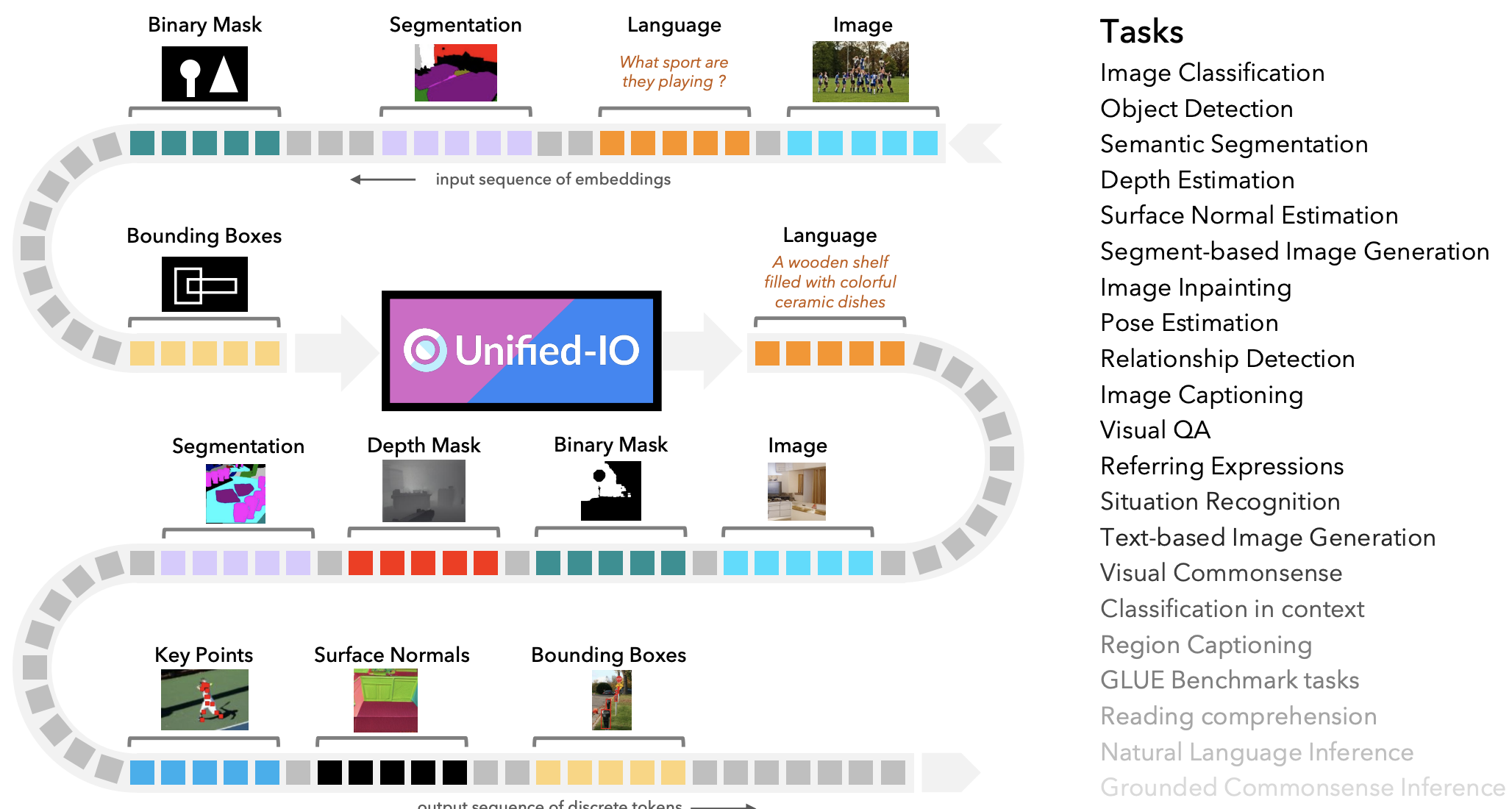
- アーキテクチャ
- Text-to-Text Transfer Transformer (T5)に従って、基本は純粋なTransformer Encoder-Decoder構造
- 画像はViTに倣ってパッチトークンにし、2次元絶対位置埋め込みを追加
- 入力は言語256画像576トークン(384x384画像から24x24パッチ)で、出力は言語128画像256トークン(256x256画像から16x16パッチ)
- パラメータ
- 学習
- 2つの事前学習
- 言語のノイズ除去(BERTと同様)
- 半分がテキストデータ(C4とWikipedia)
- 残りがImagenet21kなどの画像とクラスデータや、YFCC15Mなどの画像とキャプションデータ
- 画像のマスクノイズ除去(MAEと同様)
- 学習とデータセット
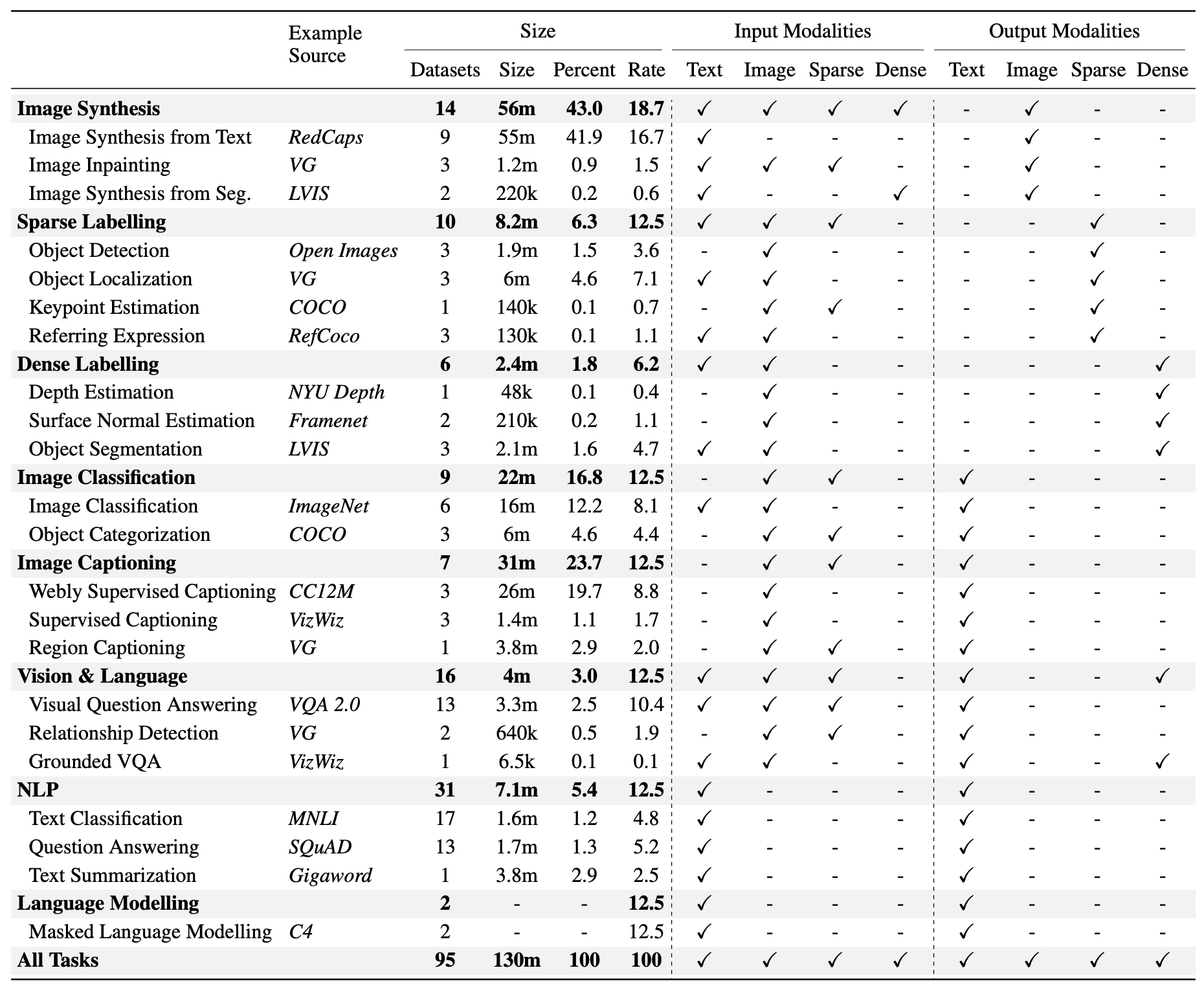
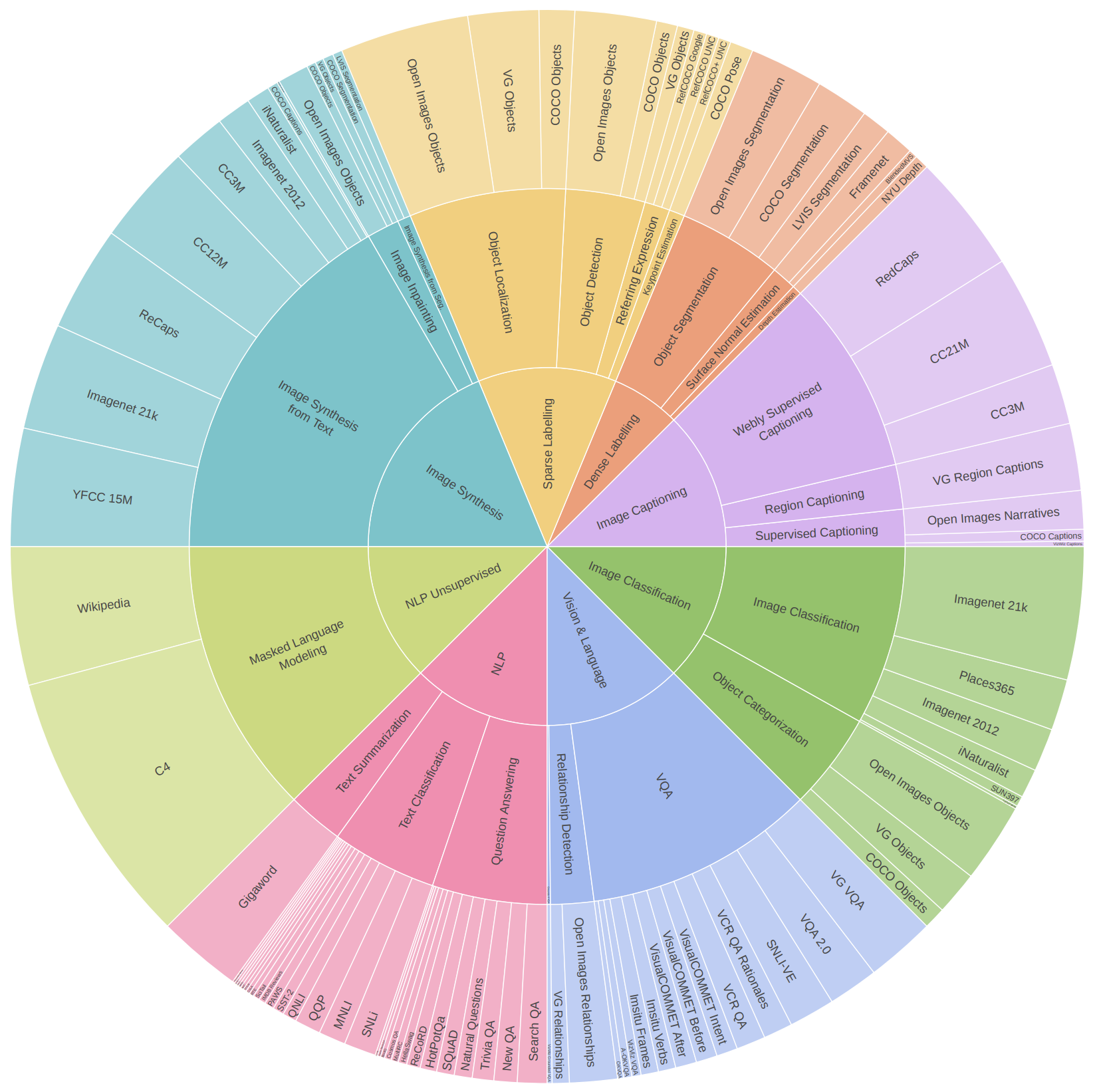
- 62箇所から95の公開データセットを使用
- バッチにデータセットを混ぜて訓練
- データの多い画像合成は3/16、少ない密度ラベリングは1/16、それ以外はグループで均等
- グループ内ではデータセットサイズの平方根に比例してサンプリング
- 一部のタスクはめったにサンプリングされない(深度推定は0.43%)
- 語彙
- 言語が32152,場所が1000,画像が16384の計49536
結果
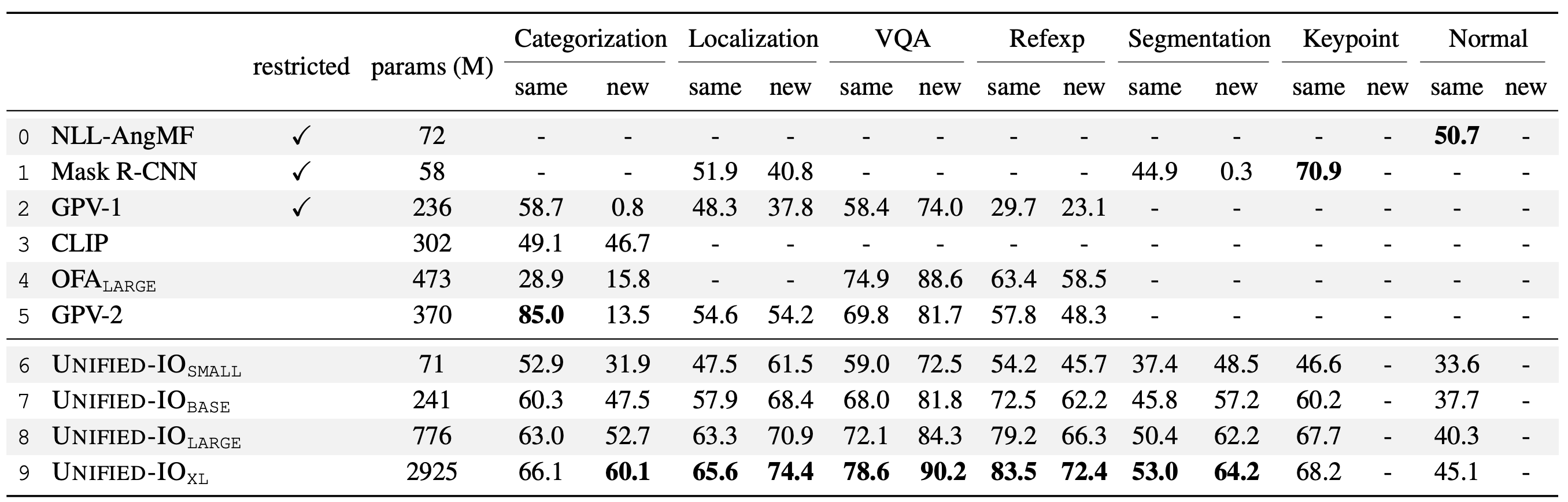
- GRIT ベンチマーク
- 画像分類、物体検出、VQA、参照表現、セグメンテーション、キーポイント、および表面法線推定など7つのタスクで構成
- 既存で最も多いGPV-2が4タスクしかできないのに対し、UNIFIED-IOは7つのタスクすべてをサポート
- UNIFIED-IO XLは画像分類、VQA、参照表現、セグメンテーションにおいてSOTA
- キーポイントはMask R-CNNより劣っている(推論が二段階のため)
- Detection
- Reration
- Other