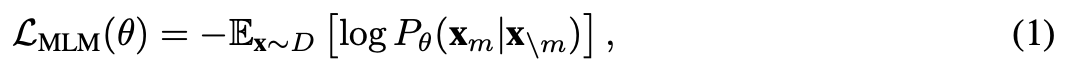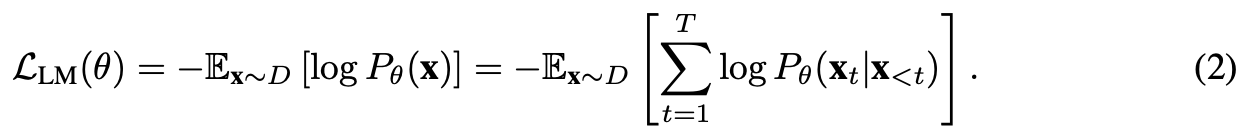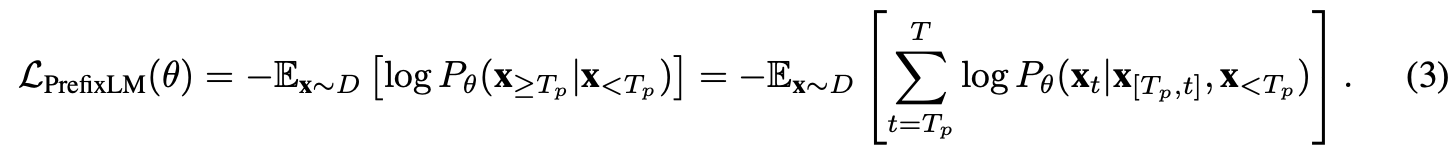SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
https://arxiv.org/abs/2108.10904
May 10, 2023
Multimodal Pretraining, Vision-Language Pretraining, Zero-shot Learning, Vision and Language,
ICLR (2022)
概要
- 最小限のVision-Language PretrainingフレームワークであるSimple Visual Language Model (SimVLM)を提案
- Prefix Language Modelingによって余分なデータやタスク固有のカスタマイズが必要ない
- 従来の事前学習方法を大幅に上回り、VQA、NLVR2、SNLI-VEなどの幅広いVLタスクでSOTA
新規性・差分
アイデア
- 背景
- Masked Language Modeling (MLM)
- BERTのように文章の一部にマスクをし、そのトークンを復元する訓練をする事前学習
- Language Modeling (LM)
- Prefix Language Modeling (PrefixLM)
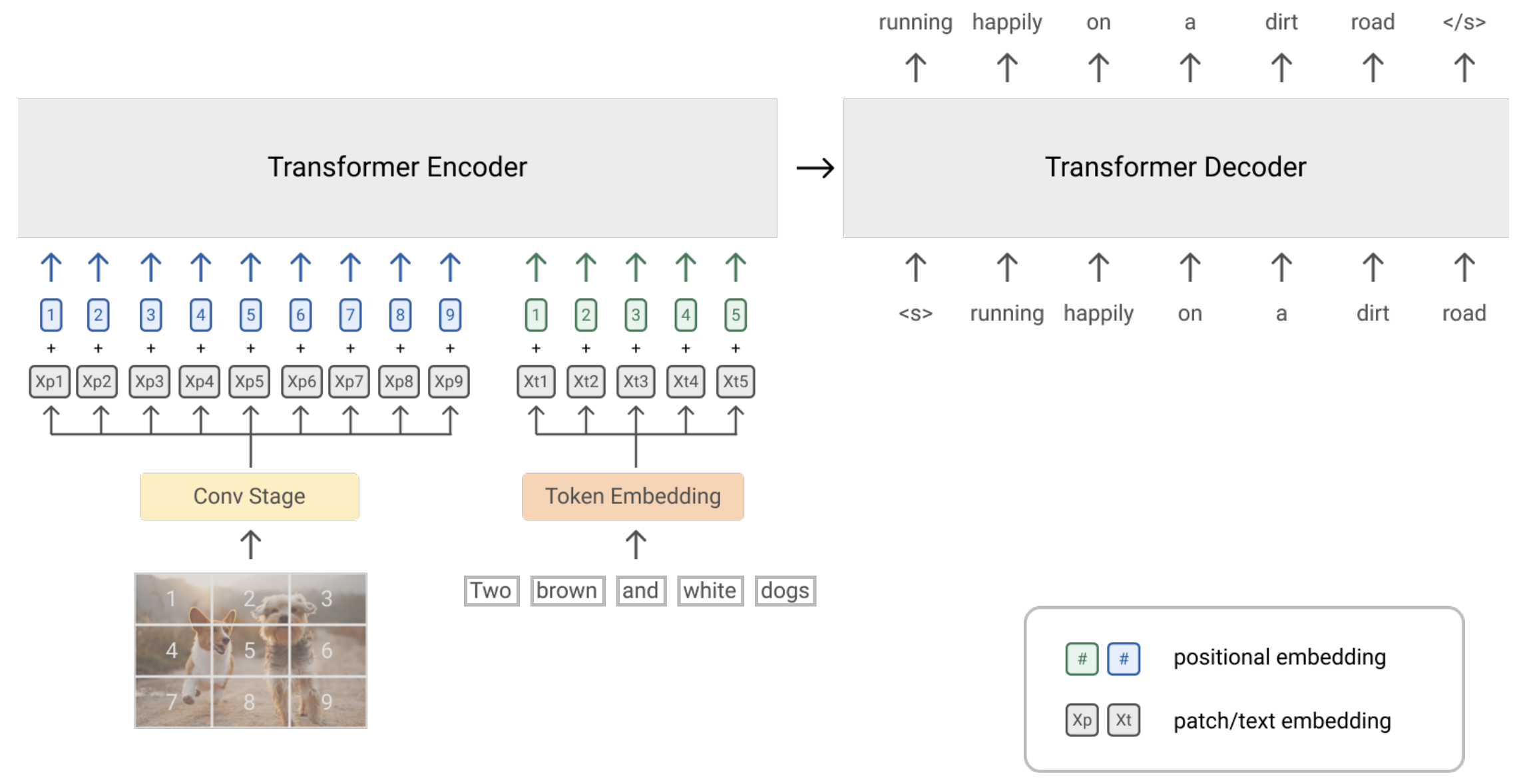
- LM Lossに倣って、下図のように、画像と文章前半を受け取り続きを予測することで、ゼロショットで画像と言語の関係を学習する
- アーキテクチャ
- 言語と画像で成功しているtransformerをバックボーンとする
- PrefixLMはDecoderのみでもEnc-Decにも適用できるが、Enc-Decの機能バイアスが下流タスクに寄与することを確認
- 画像:ResNetの最初の3つのブロックに通して、パッチ化してFlattenしてtransformerへ
- 言語:サブワードトークンにトークン化
- 画像と言語に学習可能な1D位置埋め込み
- transformerレイヤー内の画像パッチに2D相対位置埋め込み
- 学習
- ALIGINとC4データセットで1Mステップの事前学習
- 512個のTPU v3
- 4096 Img-Text(ALIGIN), 512 Text(C4)
- Finetuning後、6つのVLベンチマークで評価
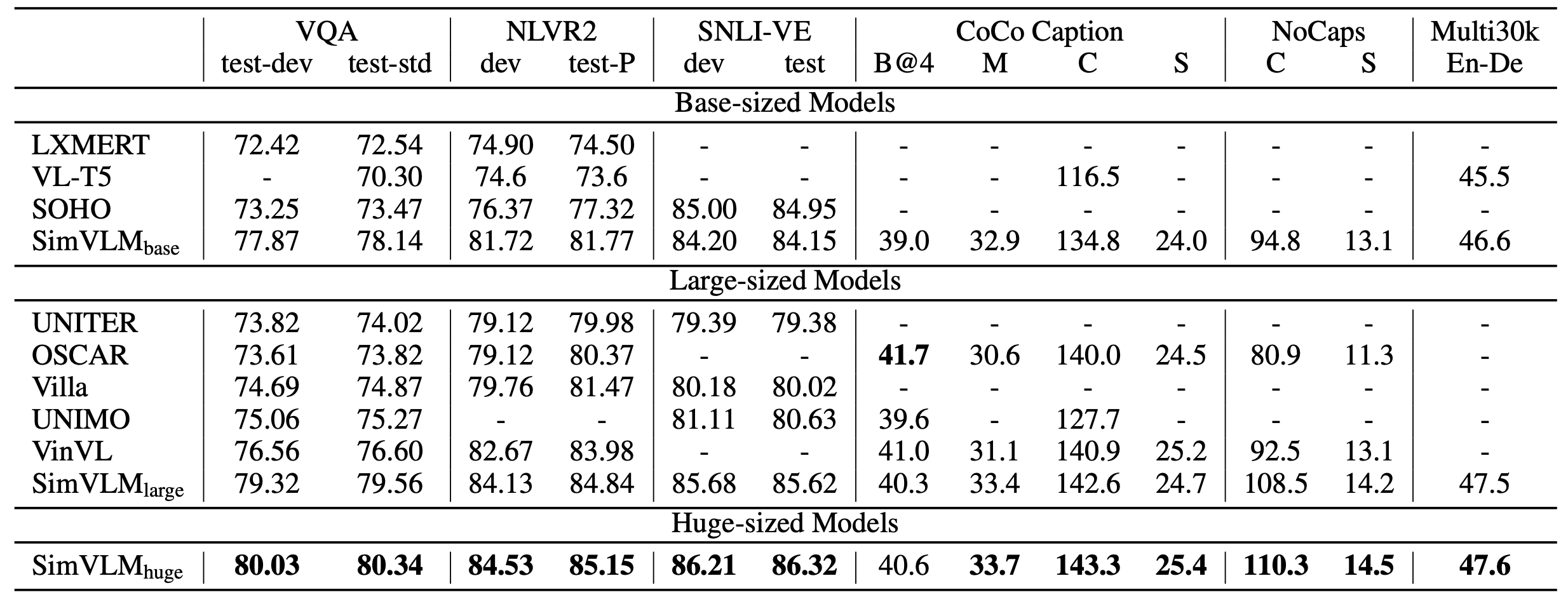
結果
- popular VL banchmarks
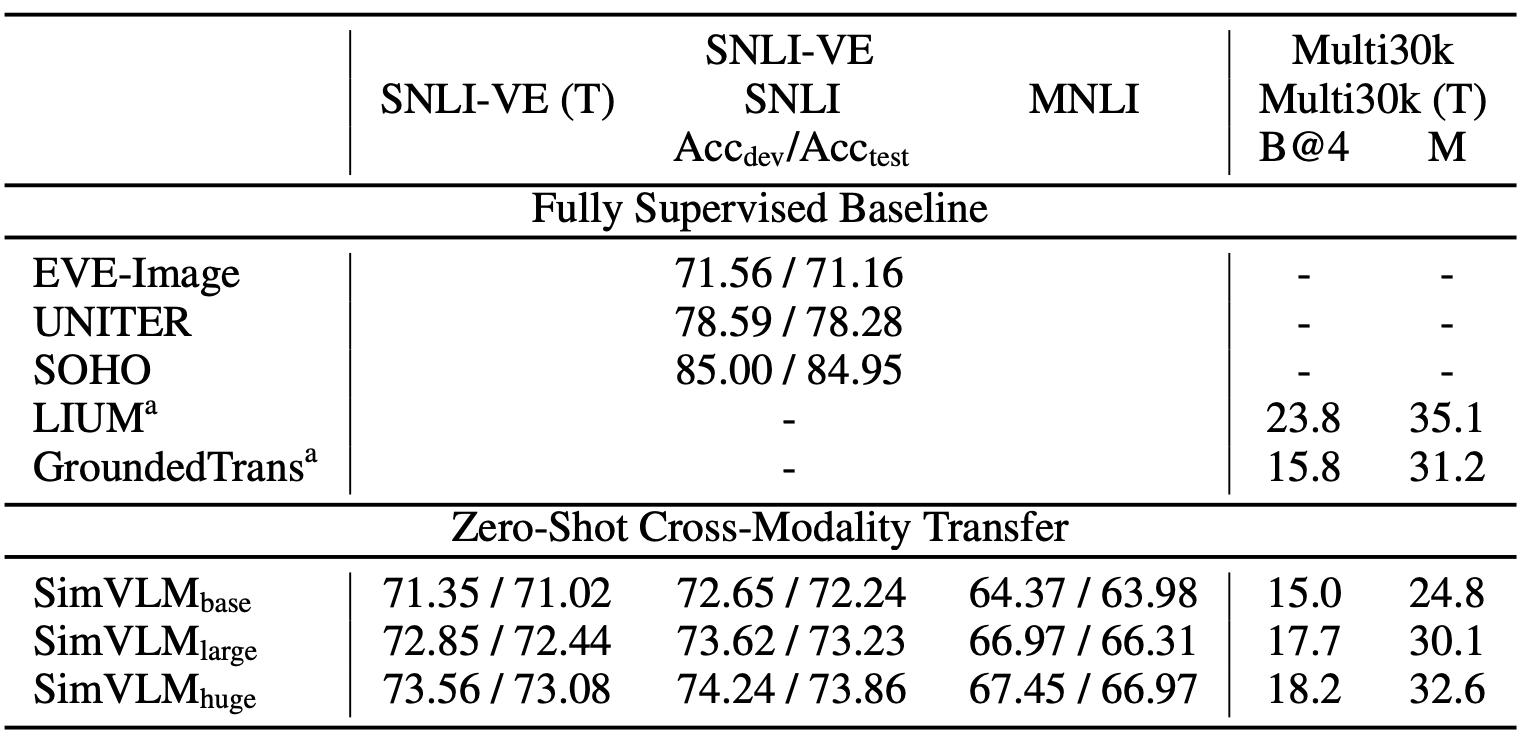
- SNLI-VE and Multi30k (Zero-shot)
- +1.37% accuracy
- VQA
- +3.74%
- ImageNet
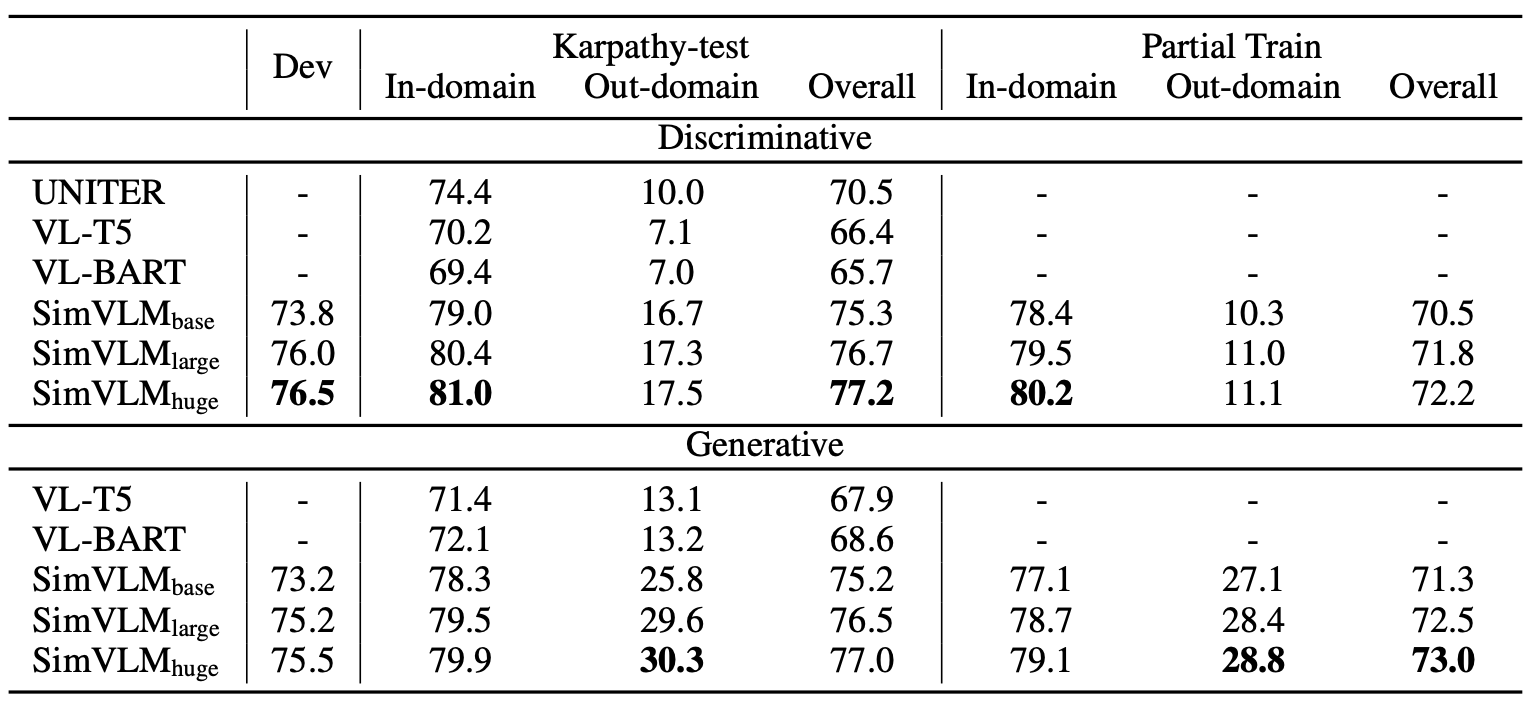
- VQA(Ablation study)
- 生成例
- (a) zero-shot image captioning (b) zero-shot cross-modality transfer on German image captioning (c) generative VQA (d) zero-shot visual text completion (e) zero-shot open-ended VQA.