OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models

OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models
https://github.com/OFA-Sys/OFASys
May 15, 2023
Multimodal Pretraining, Unified Frameworks, Vision and Language,
arXiv (2022)
概要
- マルチモーダルの汎用モデル学習システムOFASysを提案
- 7つ(TEXT、IMAGE、AUDIO、VIDEO、STRUCT、MOTION)のモダリティの23のタスク
- 複数モダリティのタスクを1行のコードで宣言することで、学習・推論用のタスクプランを自動生成する
- テキスト、画像、音声、動画、モーションデータを扱うことができる世界初の単一モデルOFA+も開発し、15個のタスクに調整されたモデルのわずか16%のパラメータで平均95%の性能を達成
新規性・差分
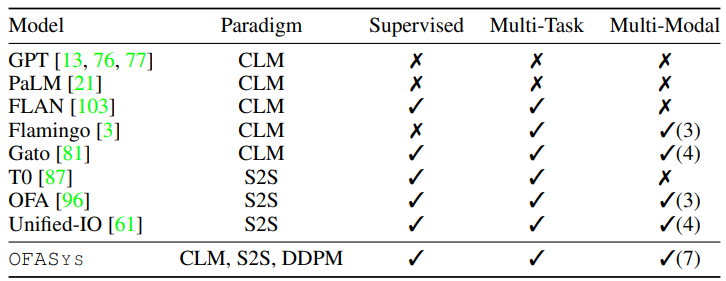
- マルチモーダル用の汎用モデル学習システムOFASysを提案
アイデア
- マルチモーダル命令
- タスクが何をするのか、データのモダリティの種類を指定する記述行
- ユーザーインターフェイス
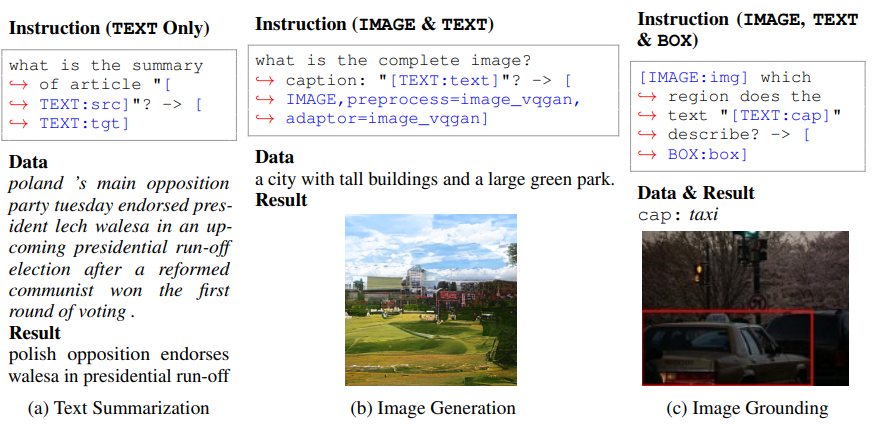
- 多様なデータやタスクに対応する命令形式(正規表現)
- 例:入力->出力(Image Caption)
- 例:可変長スロット(Object Detection)
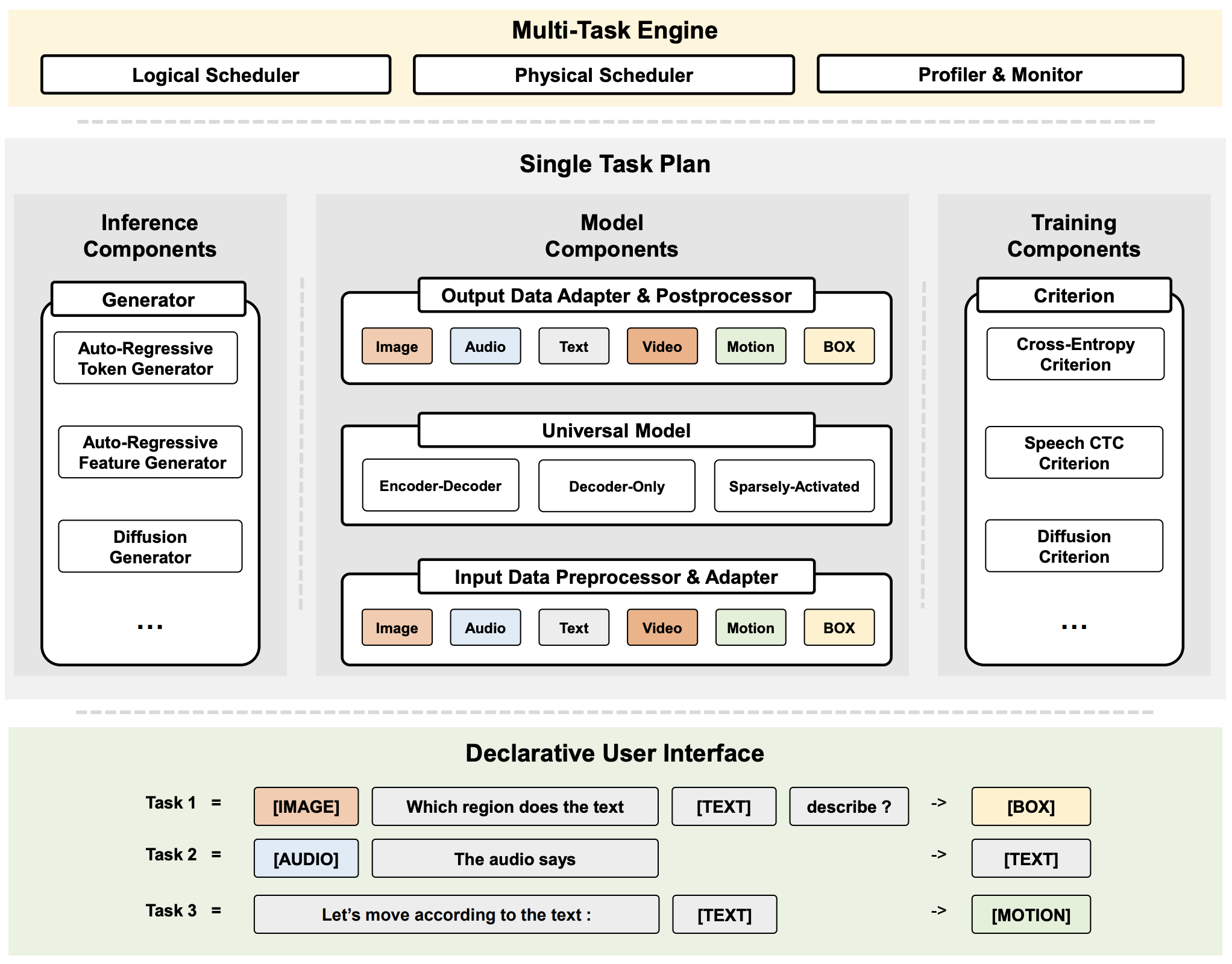
- システムデザイン
- fairseqやtransformersなどのフレームワークは開発コストを削減したが、マルチモーダルやマルチタスクではデータ処理の実装や特徴抽出器などを手動で設定しなければならない
- マルチモーダルやマルチタスクを単一のフレームワークで行なうOFASysとマルチタスク実行を管理するタスクスケジューラを開発
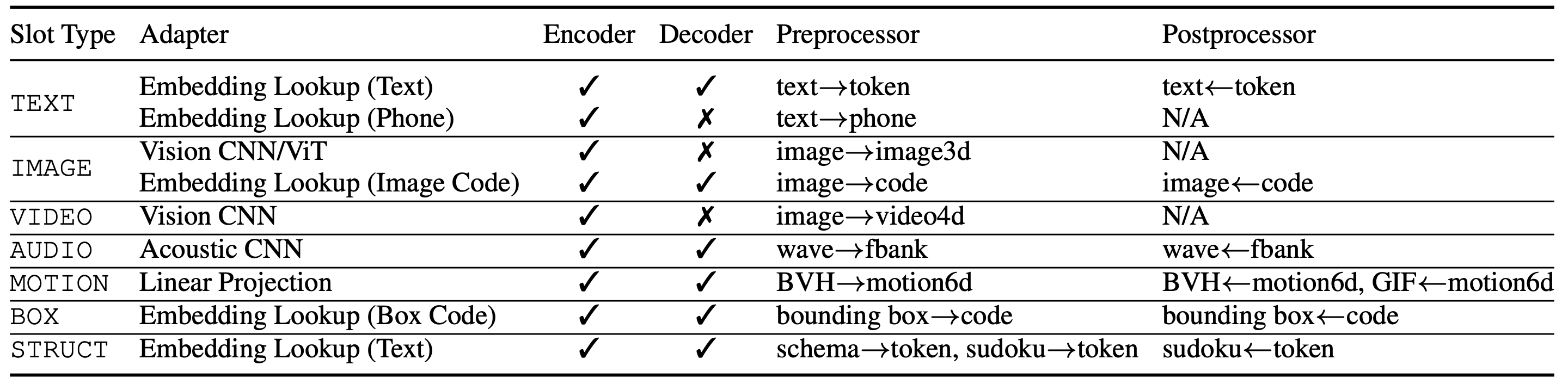
- マルチデータプロセッシング
- データの種類ごとに機械学習データに変換
- テキストならトークン、オーディオならfbank特徴
- 計算機
- T5やDiffusionに向けたU-Net、GPTなど様々なモデルに対応
- 現在はtransformer Enc-DecとMixture-of-Experts(MoE)
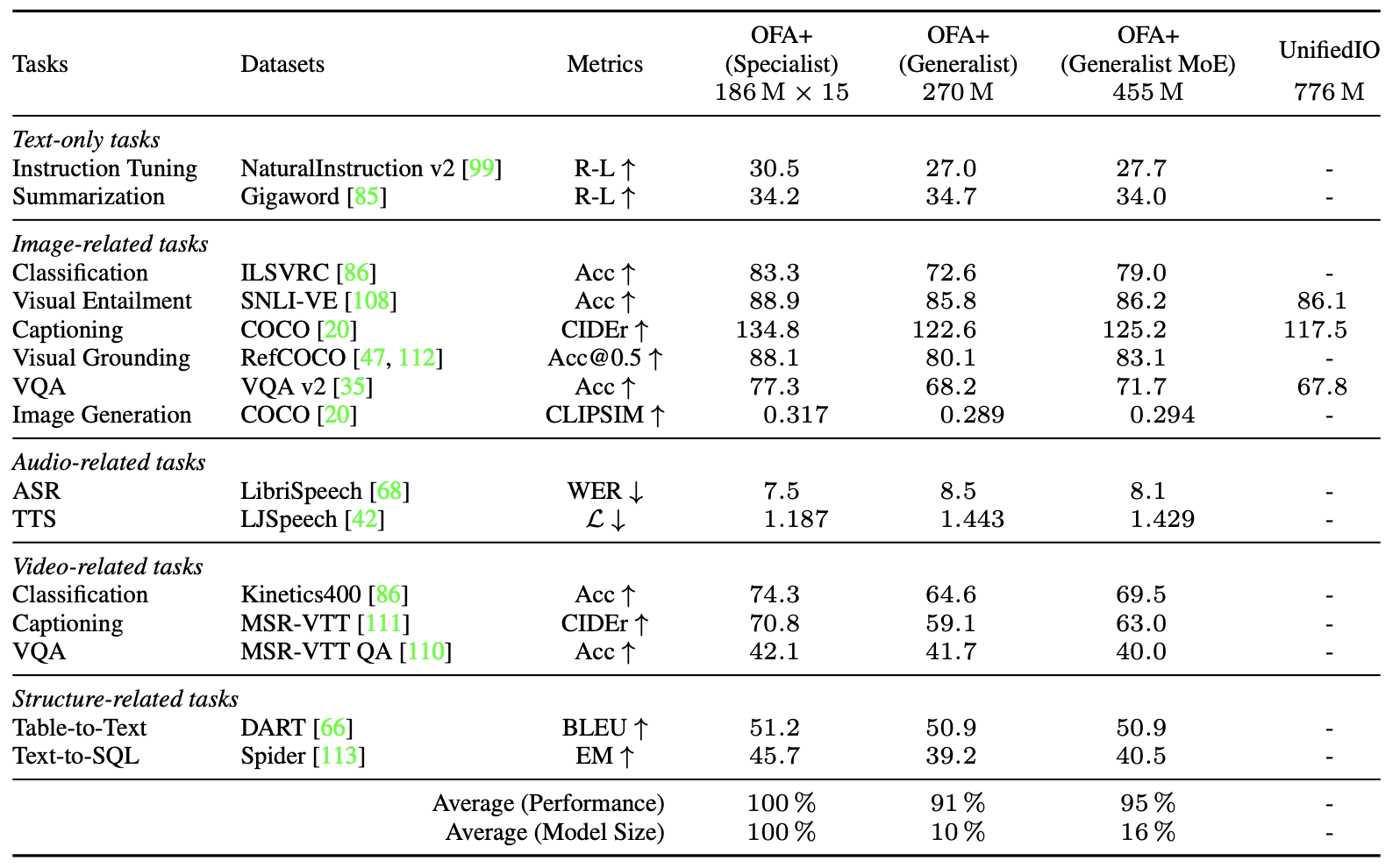
- 応用例:OFA+
- OFA-Sysを用いて、テキスト、画像、音声、動画、モーションデータをオールインワンで扱えるGeneralistモデルを学習した
- OFA+ (Generalist)
- OFA-baseの事前学習済み重みから学習
- 90/270Mがモダリティ固有のパラメータ
- OFA+ (Generalist MoE)
- OFA-baseに基づくがVLMOの実装に近い
- 275/455Mがモダリティ固有のパラメータ
- どちらも7つのモダリティの17のタスクで学習し、タスク固有のFinetuningは行わない
結果