RedCaps: Web-curated image-text data created by the people, for the people
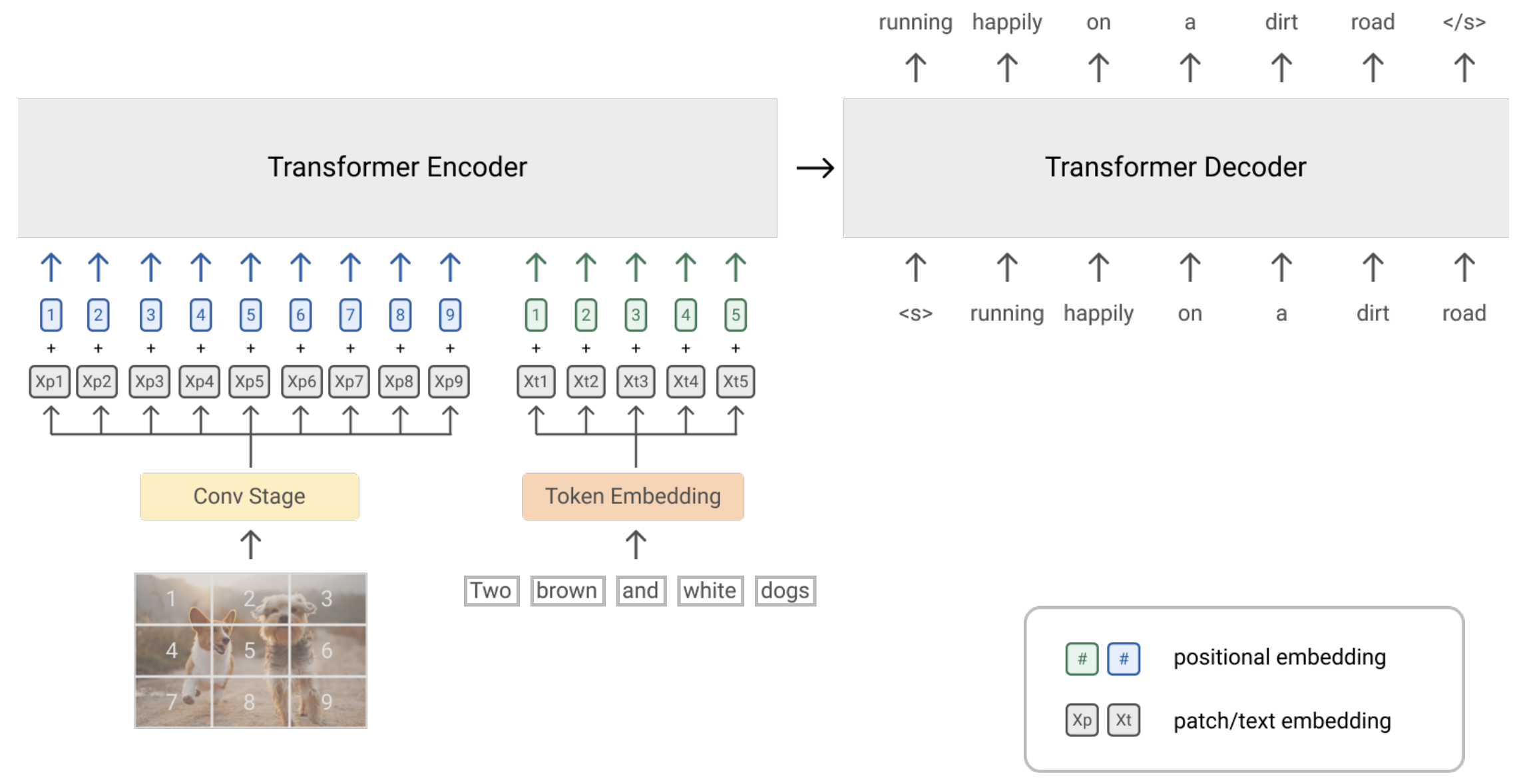
- ビジョンと言語のタスクのための大規模データセットは、検索エンジンをクエリにしたりHTMLのaltテキストを収集することで構築されているが、ウェブデータはノイズが多いため、品質を維持するために複雑なフィルタリングパイプラインが必要
- 最小限のフィルタリングで高品質なデータを収集するための代替データソースを探索
- Redditから収集された1200万の画像とキャプションのペアのRedCapsという大規模なデータセットを紹介
Jul 3, 2023 Caption NeurIPS (2021)